
Netflix, one of the world’s leading streaming platforms, is a prime example of DevOps excellence at scale. With over 200 million subscribers worldwide, Netflix faces massive demands on infrastructure, deployment speed, and application reliability. At Curiosity Tech, we analyze Netflix’s DevOps strategies to help engineers understand real-world scalability, automation, and continuous delivery practices.
Why Netflix is a DevOps Leader
Netflix’s success is underpinned by its ability to:
- Deploy Code Multiple Times a Day – Netflix engineers deploy thousands of changes weekly without downtime.
- Maintain High Availability – Systems must handle millions of simultaneous streams.
- Ensure Resilience – Automatic recovery from failures and robust disaster recovery.
- Automate Everything – From infrastructure provisioning to deployment and monitoring
Netflix showcases how DevOps, cloud, and microservices combine to enable extreme scalability and operational efficiency.
Netflix DevOps Architecture Overview
High-Level Architecture Diagram:
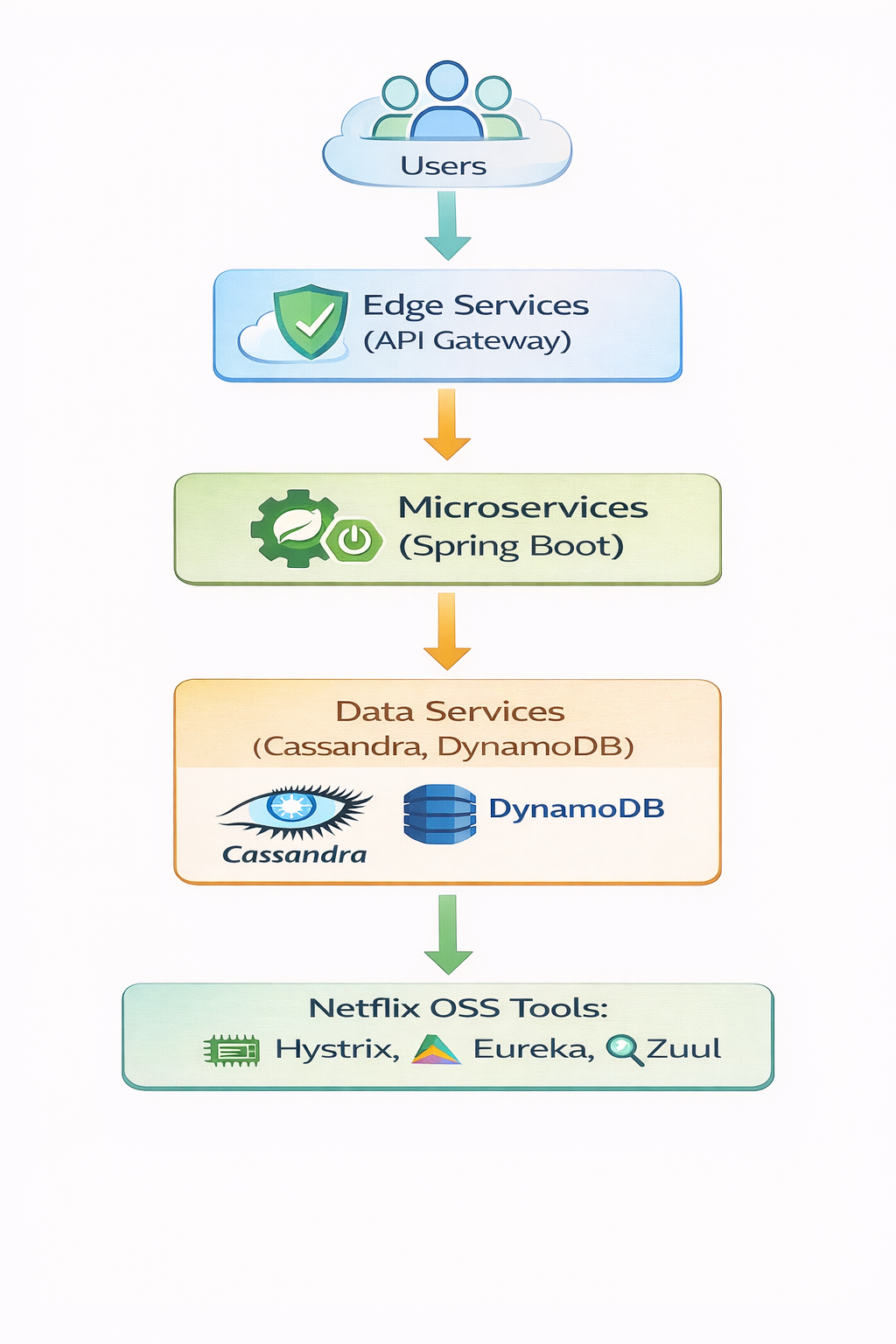
Description: Netflix employs microservices architecture, where independent services communicate via APIs. Each service is managed via DevOps pipelines and monitored continuously for performance.
Key DevOps Practices at Netflix
| Practice | Implementation | Benefit |
| Continuous Delivery | Automated pipelines for microservices deployment | Rapid code release multiple times per day |
| Infrastructure as Code | AWS + Terraform scripts | Consistent and scalable cloud infrastructure |
| Chaos Engineering | Simian Army (Chaos Monkey, Latency Monkey) | Resilience by testing failures proactively |
| Monitoring & Observability | Atlas, Spinnaker, Grafana | Real-time metrics, alerting, and dashboards |
| Microservices | Independently deployable services | Faster development cycles and fault isolation |
| Automated Testing | Unit, integration, and load tests | Reduced bugs and improved quality |
Continuous Deployment Pipeline at Netflix
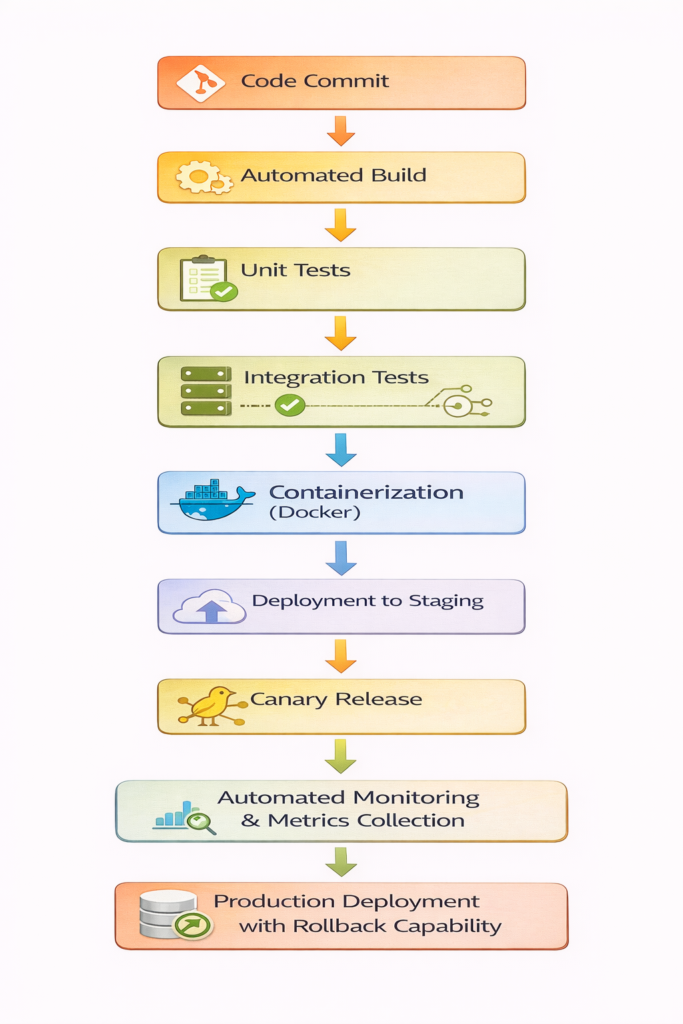
Description: Netflix deploys code multiple times daily using automated pipelines with canary releases, ensuring minimal impact on users while testing new features in production.
Scalability & Reliability Strategies
- Cloud-Native Architecture – Fully hosted on AWS, leveraging auto-scaling, load balancing, and distributed storage.
- Microservices + Containerization – Each service is independently deployable, allowing horizontal scaling.
- Chaos Engineering – Tools like Chaos Monkey simulate failures to ensure systems are resilient.
- Real-Time Monitoring – Metrics collected via Atlas and Spinnaker ensure early detection of anomalies.
- Automated Rollbacks – CI/CD pipelines automatically revert failed deployments.
Metrics Demonstrating Netflix DevOps Success
| Metric | Benchmark |
| Deployment Frequency | 1,000+ deployments per week |
| Mean Time to Recovery (MTTR) | < 30 minutes for failures |
| User Availability | 99.99% uptime |
| Incident Response Time | Immediate alerts with automated remediation |
| Microservices Count | 500+ independent services |
Lessons Learned from Netflix DevOps
- Automate Every Stage – CI/CD, monitoring, testing, and infrastructure provisioning.
- Adopt Microservices – Improves scalability, resilience, and faster deployments.
- Monitor Continuously – Real-time dashboards and alerts prevent downtime.
- Test Failures Proactively – Chaos Engineering prepares systems for unexpected events.
- Embrace Cloud Scalability – Cloud platforms like AWS provide elasticity to handle global traffic.
Conclusion
Netflix exemplifies enterprise-scale DevOps, combining CI/CD automation, IaC, microservices, monitoring, and chaos engineering to achieve unprecedented scalability and reliability. DevOps engineers can learn from Netflix’s approach by integrating automation, cloud infrastructure, and observability into their pipelines.
At Curiosity Tech, learners simulate Netflix-style DevOps scenarios, gaining hands-on experience with microservices, CI/CD pipelines, automated monitoring, and cloud deployments—preparing them for real-world large-scale DevOps challenges.