
Introduction
In 2025, feature engineering and selection are the secret weapons of successful data scientists. Raw data rarely contains ready-to-use variables for machine learning models. Transforming and selecting the right features can dramatically improve model accuracy, efficiency, and interpretability.
At Curiosity Tech, Nagpur (1st Floor, Plot No 81, Wardha Rd, Gajanan Nagar), our learners master feature engineering and selection techniques using Python and R, ensuring their models are robust and production-ready.
This blog provides a deep dive into feature engineering, selection strategies, workflows, and practical examples to make you proficient.
Section 1 – What is Feature Engineering?
Definition: Feature engineering is the process of creating new input variables (features) or transforming existing ones to make machine learning models more effective.
Analogy: Think of features as ingredients in a recipe. Even the best model (chef) cannot make a delicious dish if the ingredients (features) are poor or irrelevant.
Types of Feature Engineering:
- Transformation: Applying log, sqrt, or normalization
- Encoding Categorical Variables: One-hot, label encoding, or target encoding
- Creating Interaction Features: Combining two or more features
- Aggregations: Summarizing data with mean, sum, count
- Temporal Features:-
- Example:– Raw feature: Date_of_Sale→ Engineered features: Month, Day_of_Week, Is_Weekend
Section 2 – Why Feature Engineering Matters
- Improves model performance: Better features → higher predictive power
- Reduces overfitting: Remove irrelevant or redundant features
- Speeds up training: Fewer but informative features reduce computational cost
- Enhances interpretability: Models with clear features are easier to explain
CuriosityTech Story:- A learner applied feature engineering to e-commerce sales data, creating features like Average_Purchase_Per_Customer and Days_Since_Last_Purchase. The model’s R² improved from 0.62 to 0.81, demonstrating the power of thoughtful feature engineering.
Section 3 – Feature Selection Techniques
Feature selection is the process of choosing the most relevant features to include in your model.
1. Filter Methods
- Select features based on statistical measures
- Examples:
- Correlation Coefficient:- Remove features with low correlation to target.
- Chi-Square Test:- For categorial features.
- Variance Threshold:- Remove features with low variability.
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(threshold=0.1)
X_new = selector.fit_transform(X)
2. Wrapper Methods
- Select features by evaluating model performance iteratively.
- Examples:
- Forward Selection:- Add features incrementally.
- Backward Elimination:- Remove least important features.
- Recursive Features Elimination:- Iteratively remove weak features.
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
model = LinearRegression()
rfe = RFE(model, n_features_to_select=5)
X_selected = rfe.fit_transform(X, y)
3. Embedded Methods
- Feature selection occurs during model training
- Examples:
- Lasso Regression:- Penalizes less important feature.
- Tree-Based Models:- Feature importance based on splits.
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X, y)
importances = model.feature_importances_
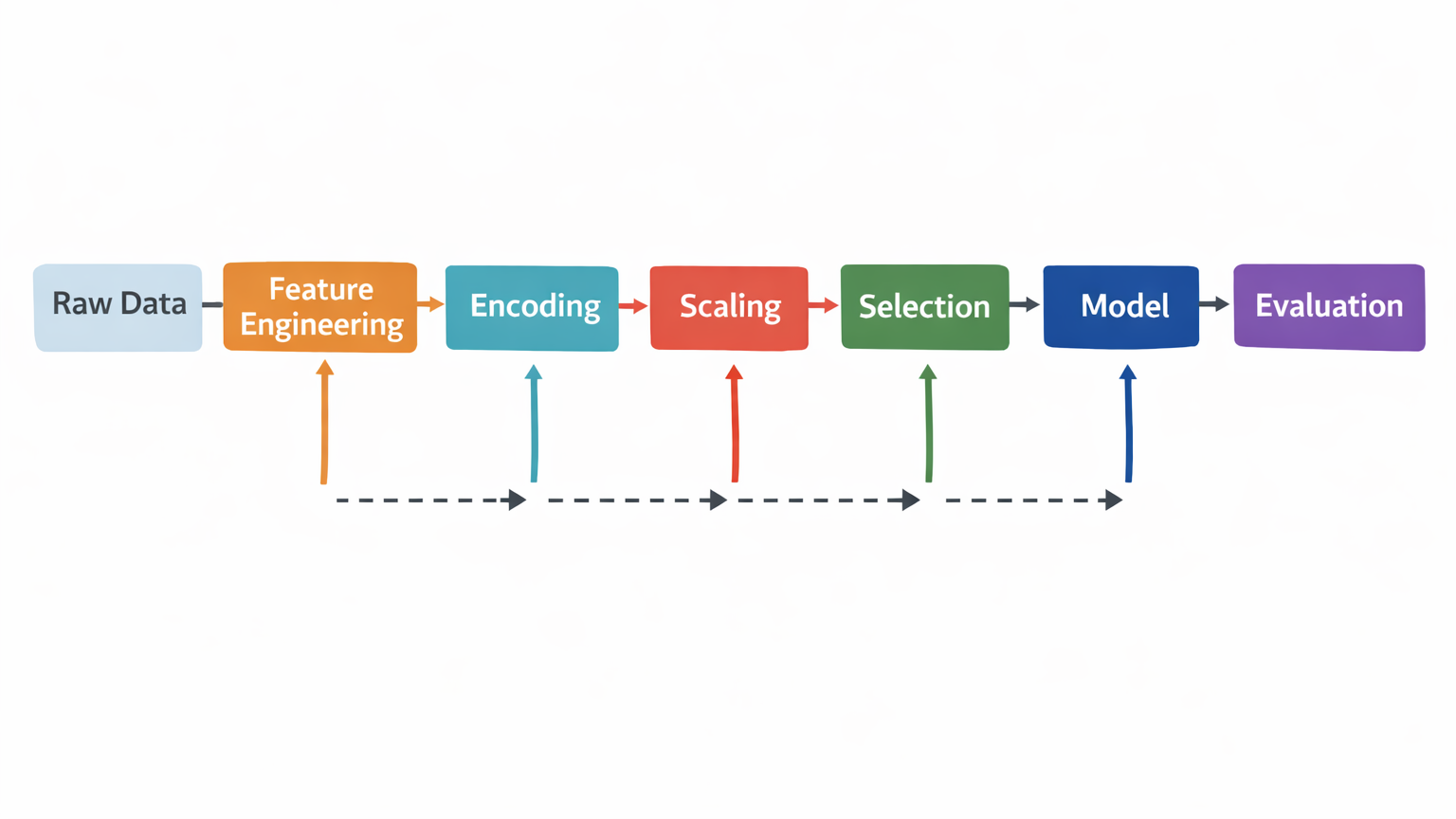
Section 4 – Practical Workflow for Feature Engineering & Selection
- Data Understanding: Identify types (numeric, categorical, temporal)
- Initial Cleaning: Handle missing values, outliers
- Create New Features: Apply domain knowledge for meaningful features
- Feature Encoding: Transform categorical variables for models
- Feature Scaling: Normalize or standardize if required
- Feature Selection: Apply filter, wrapper, or embedded methods
- Evaluate Model Performance: Compare model metrics before and after selection
- Iterate & Optimize: Refine features and selection based on results
Workflow Diagram Description:
Section 5 – Example: Predicting Loan Defaults
Dataset Features: Income, Credit_Score, Employment_Status, Age, Loan_Amount, Loan_Term
Feature Engineering:
- Debt_to_Income_Ratio = Loan_Amount ÷ Income
- Is_Employed = 1 if Employment_Status is “Employed”, else 0
- Loan_Term_in_Months = convert years to months
Feature Selection (Python):
from sklearn.feature_selection import SelectKBest, f_classif
X_new = SelectKBest(score_func=f_classif, k=5).fit_transform(X, y)
Impact: The model trained on engineered and selected features improved accuracy from 78% to 87%.
Section 6 – Advanced Tips
- Domain Knowledge is Key: Engineering features requires understanding business context
- Automate Repetitive Transformations: Use pipelines (sklearn.pipeline)
- Handle Multicollinearity: Remove highly correlated features to improve model stability
- Feature Importance Visualization: Use bar plots to understand contribution
- Iterative Process: Feature engineering and selection are never one-time tasks
CuriosityTech Tip: Learners at our institute practice feature engineering on multiple domains—finance, healthcare, retail—creating strong portfolios for 2025 data science roles
Section 7 – Tools and Libraries
Python:
- Pandas, NumPy for transformations
- Scikit-Learn for feature selection and encoding
- Feature-engine for automated engineering
R:
- dplyr and tidyr for feature creation
- caret package for feature selection
- recipes for pipelines and preprocessing
Section 8 – Real-World Impact Story
A CuriosityTech learner applied feature engineering and selection to a marketing dataset.
- Created features like Avg_Spend_Last_3_Months and Customer_Loyalty_Score
- Used RFE to select top 8 features
- Outcome: Model predicted high-value customers 30% more accurately, enabling targeted campaigns and higher ROI
Conclusion
Feature engineering and selection are critical skills for every data scientist in 2025. With the right approach, you can boost model accuracy, interpretability, and business impact.
At Curiosity Tech Nagpur, learners gain hands-on experience, mentorship, and project guidance to master feature engineering and selection, preparing them to excel in data science roles. Contact +91-9860555369, contact@curiositytech.in, and follow Instagram: CuriosityTechPark or LinkedIn: Curiosity Tech for updates.