
Introduction
In deep learning, activation functions are the decision-makers of neural networks. They determine whether a neuron should “fire” and pass information forward. Without them, even the most complex neural network reduces to a linear model, unable to capture the intricacies of images, text, or sequential data.
At CuriosityTech.in, where students in Nagpur explore both theory and hands-on projects, understanding activation functions is the turning point from beginner to intermediate AI proficiency. Whether in TensorFlow, PyTorch, or any other framework, knowing which activation function to use can make the difference between a model that succeeds and one that fails.
1. What Are Activation Functions?
Activation functions are mathematical formulas that decide how the weighted sum of inputs should be transformed into an output for the next layer.
- Think of neurons like gatekeepers:
- Some gates are strict (fire only for high values).
- Some gates are smooth (gradually respond).
- Some normalize outputs (convert raw scores to probabilities).
- Key Roles:
- Introduce non-linearity to neural networks.
- Allow the network to model complex relationships.
- Help in training convergence and gradient flow.
2. Popular Activation Functions
A. Sigmoid Function
- Formula: σ(x)=11+e−x\sigma(x) = \frac{1}{1 + e^{-x}}σ(x)=1+e−x1
- Range: 0 → 1
- Use Case: Binary classification, probability outputs
- Pros: Smooth gradient, outputs probabilities
- Cons: Prone to vanishing gradient problem, saturates at extremes
Practical Example: Predicting whether an email is spam or not (1 = spam, 0 = not spam).
B. ReLU (Rectified Linear Unit)
- Formula: f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x)
- Range: 0 → ∞
- Use Case: Hidden layers in deep networks, CNNs
- Pros: Fast computation, mitigates vanishing gradient
- Cons: Can cause dying ReLU problem (neurons stuck at 0)
Analogy: A switch that only activates if the input exceeds a threshold.
C. Softmax Function
- Formula: Softmax(xi)=exi∑jexj\text{Softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}}Softmax(xi)=∑jexjexi
- Range: 0 → 1 (sum = 1)
- Use Case: Multi-class classification
- Pros: Converts raw logits into probabilities, interpretable
- Cons: Sensitive to outliers, can be computationally expensive
Example: Classifying handwritten digits (0–9) in MNIST dataset.
3. Comparison Table
| Activation Function | Formula | Output Range | Pros | Cons | Use Case |
| Sigmoid | 1 / (1 + e^-x) | 0 – 1 | Smooth, probability | Vanishing gradient | Binary classification |
| ReLU | max(0, x) | 0 – ∞ | Fast, non-linear | Dying neurons | Hidden layers, CNNs |
| Softmax | e^x_i / Σ e^x_j | 0 – 1 (sum=1) | Probabilities, interpretable | Sensitive to outliers | Multi-class classification |
4. Activation Functions in Practice
At CuriosityTech.in, learners experiment with each function to see its impact on model accuracy and convergence.
Example:
- Using Sigmoid in a deep CNN caused slow convergence.
- Switching hidden layers to ReLU improved training speed and accuracy.
- Output layer with Softmax ensured interpretable probabilities for classification.
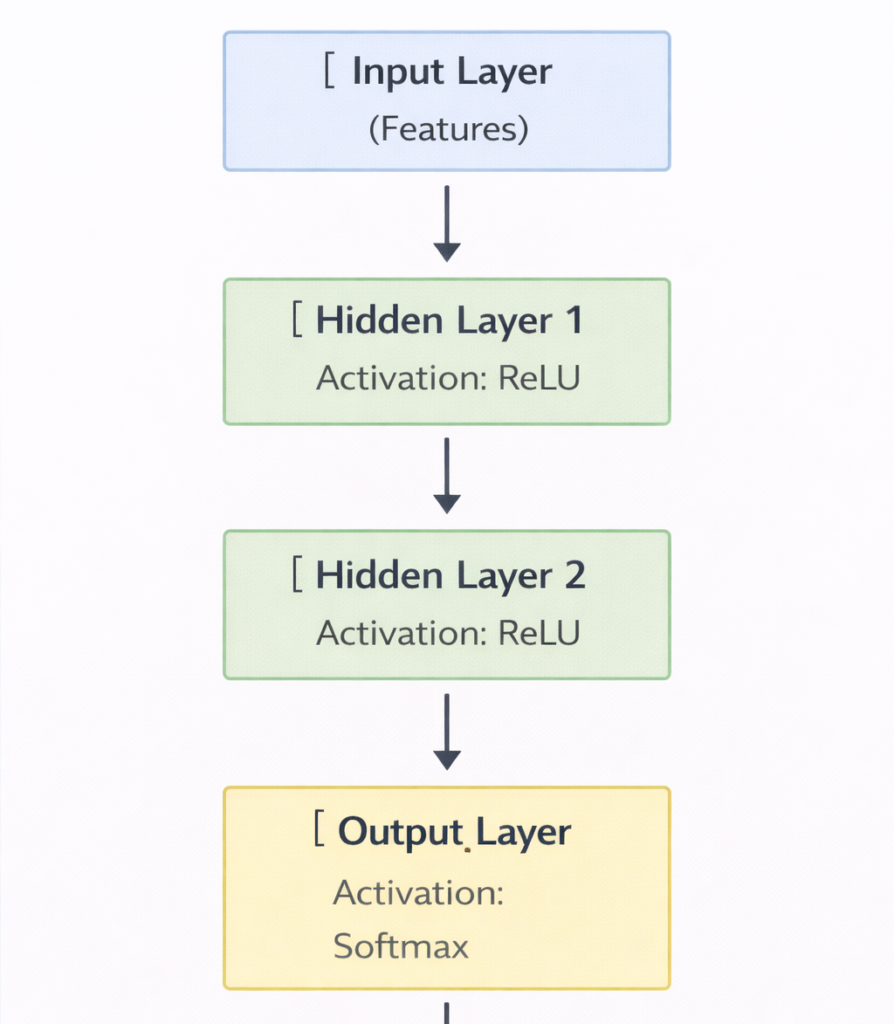
5. Choosing the Right Activation Function
| Layer Type | Recommended Activation |
| Input / Hidden | ReLU, Leaky ReLU, ELU |
| Output (Binary) | Sigmoid |
| Output (Multi- class) | Softmax |
| Regression | Linear |
Pro Tip: Always experiment with variations like Leaky ReLU or ELU to avoid problems like “dead neurons.”
6. Common Mistakes Beginners Make
- Using Sigmoid in hidden layers → leads to vanishing gradients
- Not normalizing input data → causes exploding outputs
- Forgetting activation in output layer → wrong model behavior
At CuriosityTech, mentors guide learners to diagnose and debug these mistakes using visualization tools like TensorBoard.
7. Applied Career Insight
For aspiring Deep Learning Engineers:
- Understanding activation functions is critical for interview questions and practical model building.
- Experimenting on datasets like CIFAR-10, IMDB sentiment, or MNIST helps build a portfolio.
- Practical experience with TensorFlow, PyTorch, and Keras accelerates the journey from beginner to expert.
8. Human Story
A student in our Nagpur labs once built a text classifier. Initially, using Sigmoid for multi-class classification led to 40% accuracy.
After switching to Softmax, the accuracy jumped to 92%. This small change demonstrated the huge practical impact of activation functions—and the importance of mentorship, like that provided by CuriosityTech.in.
Conclusion
Activation functions are the heart of neural networks. Understanding Sigmoid, ReLU, and Softmax is essential for building models that are accurate, efficient, and scalable. For beginners, hands-on practice with these functions, combined with mentorship and projects at CuriosityTech.in, creates a solid foundation for a successful AI career.