

Introduction
Disasters in the cloud are not “if” events but “when” events. Outages at AWS, GCP, or Azure do happen, sometimes lasting hours and costing organizations millions.
Multi-cloud provides resilience but resilience works only when supported by a structured Disaster Recovery (DR) strategy.
At Curiosity Tech we guide enterprises and learners to design DR strategies as living playbooks—documents that can be executed, tested, and continuously improved, not just filed away.
This blog serves as a comprehensive Disaster Recovery Playbook for multi-cloud environments.
1 – Core DR Concepts
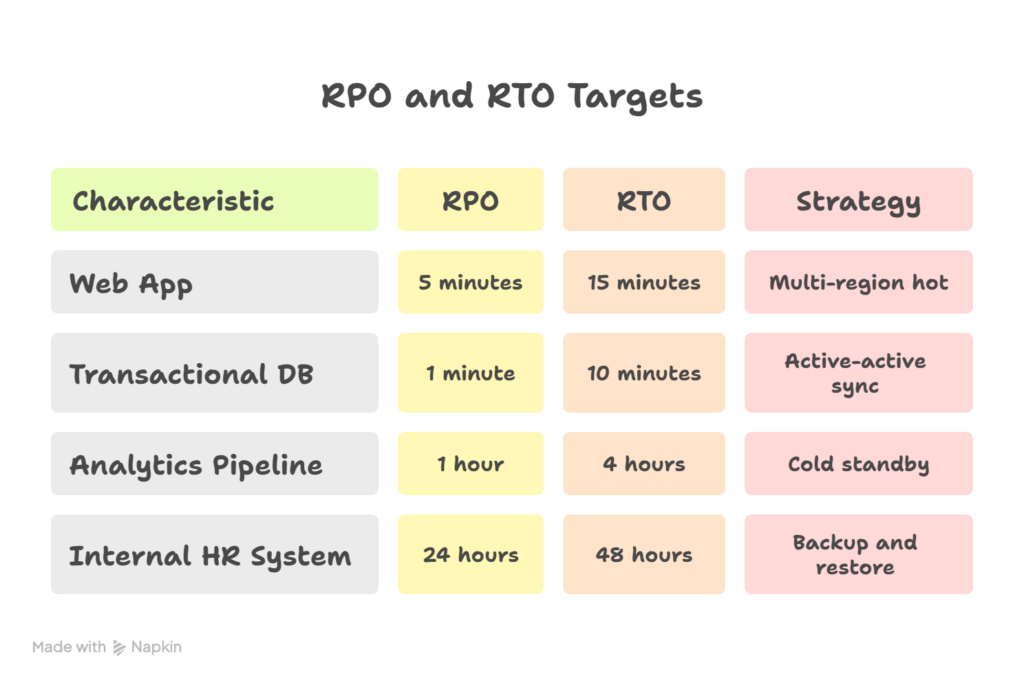
- RPO (Recovery Point Objective): Maximum acceptable data loss, measured in time
- RTO (Recovery Time Objective): Maximum acceptable downtime, measured in time
- Hot, Warm, Cold Sites: Different levels of failover readiness
- Business Impact Analysis (BIA): Identifies critical workloads and their disaster recovery requirements
Table Example: RPO and RTO Targets
2 – Multi-Cloud DR Strategy Tiers
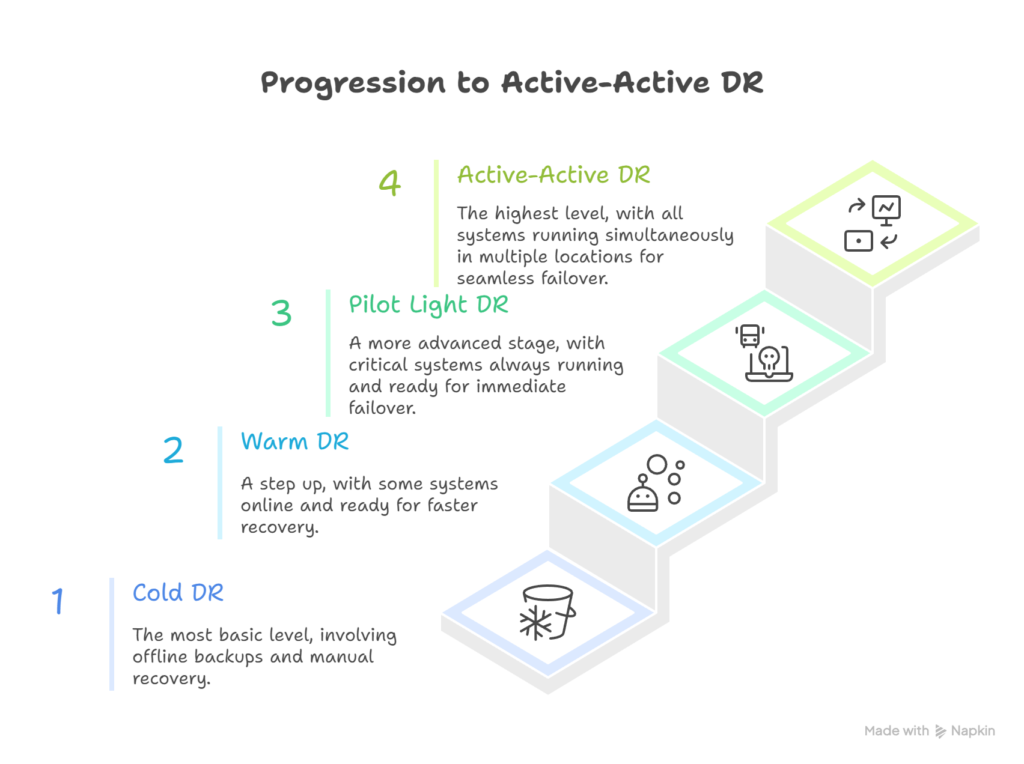
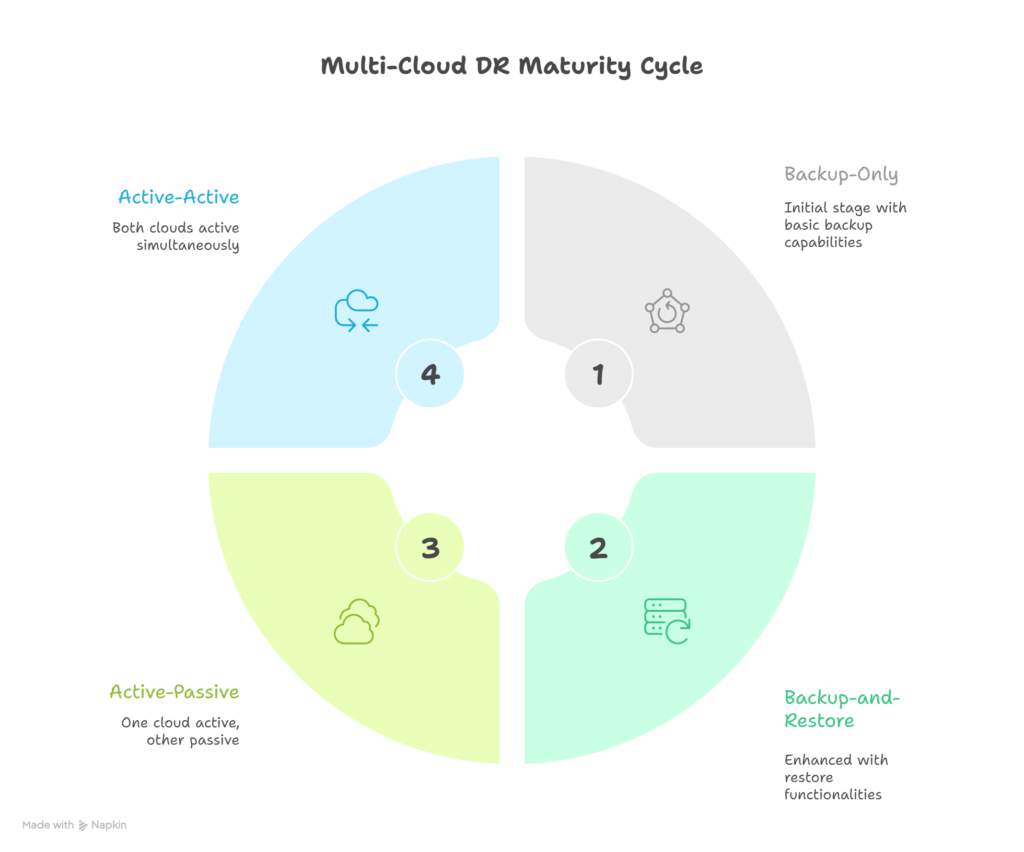
- Backup-Only (Cold DR):- Backups are stored in a secondary cloud. This is the cheapest option but has the slowest recovery time.
- Warm Standby:- Minimal resources are pre-provisioned in a secondary cloud, offering faster recovery at moderate cost.
- Pilot Light:- Core systems such as databases run continuously in the secondary cloud, allowing rapid scaling during a disaster.
- Active-Active (Hot DR):- Applications run fully in multiple clouds simultaneously, delivering near-zero downtime at a higher cost.
Section 3 – Disaster Recovery Playbook Steps
1 – Risk Assessment
- Identify single points of failure
- Analyze cloud-region risks (for example, historical issues in AWS us-east-1)
2 – Classify Applications
- Tier 1: Mission-critical applications use Active-Active strategies
- Tier 2: Important applications tolerate limited downtime using Warm Standby
- Tier 3: Non-critical applications use Cold DR
3 – Design DR Architectures
- Databases use cross-cloud replication (AWS RDS to GCP Cloud SQL)
- Storage syncs data across clouds using tools like S3 and GCP Cloud Storage
- Networking uses multi-cloud DNS failover with Route 53 or Cloudflare
4 – Document Failover Procedures
Clear, human-readable steps such as:
- Detect outage using monitoring alerts
- Confirm via cloud provider status pages
- Trigger DNS failover to the secondary cluster
- Validate traffic shift and application health
5 – Test Regularly
- Conduct quarterly failover drills
- Use chaos engineering to simulate region failures
- Perform post-mortems and update the playbook
4 – Tools for Multi-Cloud DR
- Data Replication tools include CloudEndure, Velero, and gsutil or rsync
- Databases can use active-active designs with CockroachDB, Yugabyte, or native cloud replication
- Orchestration is automated using Terraform for rapid environment rebuilds
- Monitoring is centralized using Prometheus and Grafana across clouds
At CuriosityTech.in workshops, real DR failovers are simulated by intentionally shutting down AWS EC2 clusters and observing workloads shift seamlessly to GCP using DNS automation.
5 – Example DR Scenario
An e-commerce company runs its frontend in AWS us-east-1 and its backend in GCP.
During an AWS us-east-1 outage:
- Route 53 detects the failure
- Traffic fails over to the frontend running in GCP Cloud Run
- The backend remains unaffected
- RPO is met with no data loss due to active replication
- RTO is achieved in approximately 12 minutes
6 – Human Factors in DR
Roles and responsibilities must be defined in advance:
- Disaster Recovery Lead
- Cloud Operations Engineer
- Communications Officer
- Business Stakeholder
A clear communication plan includes:
- Slack or Microsoft Teams war rooms
- External customer communications
- Incident and ticket tracking
At CuriosityTech Nagpur, learners participate in tabletop exercises that simulate real outage scenarios and role-based response coordination.
7 – Pitfalls to Avoid
- Assuming cloud platforms guarantee zero downtime
- Ignoring cross-cloud data egress costs
- Over-engineering DR solutions, increasing costs unnecessarily
- Under-testing DR plans
- Lacking centralized and updated documentation
8 – Maturity Model for Multi-Cloud DR
Diagram (described):- A four-step staircase representing progression from Backup-Only to Active-Active DR maturity.
Conclusion
Disaster Recovery in multi-cloud environments is built on discipline and preparation. It requires not only technology but also people, processes, and continuous testing.
While Kubernetes, serverless platforms, and managed databases simplify implementation, true resilience is proven only during real incidents.At Curiosity Tech we go beyond theory by training professionals to design, test, and operate DR strategies in live multi-cloud labs—because resilience is earned, not purchased.
At Curiosity Tech we go beyond theory by training professionals to design, test, and operate DR strategies in live multi-cloud labs—because resilience is earned, not purchased.

