

Introduction
In 2025, building machine learning models is just one part of the process. ML pipelines and workflow automation ensure that models are reproducible, scalable, and production-ready.
At CuriosityTech.in (Nagpur, Wardha Road, Gajanan Nagar), we train ML engineers to understand the complete workflow—from data ingestion to model deployment—while automating repetitive tasks, saving time and reducing errors.
1. What is an ML Pipeline?
Definition : An ML pipeline is a sequence of automated steps for preparing data, training models, validating performance, and deploying them.
Benefits:
- Ensures reproducibility
- Reduces human errors
- Facilitates continuous integration and deployment (CI/CD)
- Speeds up experimentation and model iteration
CuriosityTech Insight: Students at CuriosityTech learn that pipelines transform a chaotic ML workflow into a structured, repeatable process, crucial for enterprise-scale ML.
2. Core Components of an ML Pipeline
| Stage | Purpose | Tools/Techniques |
| Data Ingestion | Collect raw data from sources | APIs, databases, CSV files |
| Data Preprocessing | Clean, transform, normalize | Pandas, NumPy, Scikit-learn |
| Feature Engineering | Extract and select features | Feature scaling, encoding, embeddings |
| Model Training | Fit models to processed data | Scikit-learn, XGBoost, TensorFlow, PyTorch |
| Model Evaluation | Assess performance | Accuracy, F1-score, ROC-AUC |
| Model Deployment | Serve models in production | Flask, FastAPI, Docker, Kubernetes |
| Monitoring & Maintenance | Track model performance and drift | Prometheus, Grafana, MLflow |
3. Stepwise Workflow Automation
Diagram Description:
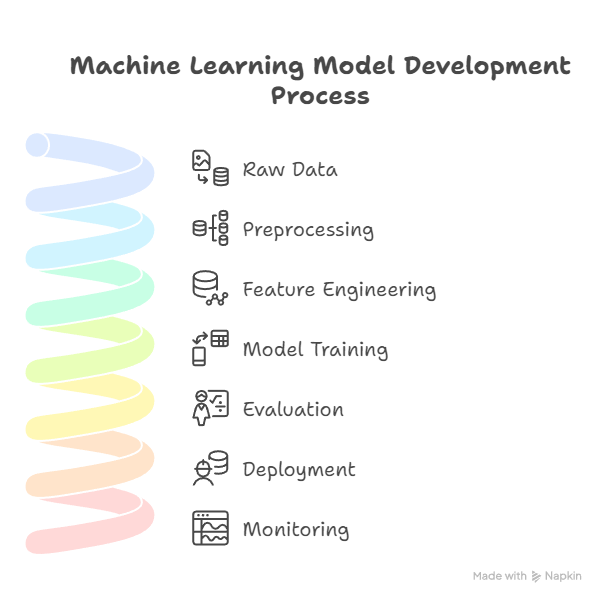
Raw Data → Preprocessing → Feature Engineering → Model Training → Evaluation → Deployment → Monitoring
- Each step is modular and automated
- Arrows indicate data flow and dependencies
- Optional loops for feedback and retraining
Scenario Storytelling :- Arjun at CuriosityTech Park automates a customer churn prediction pipeline. Once new data arrives, preprocessing, retraining, and evaluation occur automatically, reducing manual intervention.
4. Automation Tools and Frameworks
| Tool | Purpose | Notes |
| Airflow | Workflow orchestration | Schedule pipelines and manage dependencies |
| Kubeflow | End-to-end ML pipeline orchestration | Supports large-scale ML workflows |
| MLflow | Model tracking and management | Track experiments, version models |
| Prefect | Task automation | Easier setup than Airflow for lightweight workflows |
| Docker & Kubernetes | Containerize and orchestrate models | Ensures reproducibility and scalability |
At CuriosityTech.in, students implement Airflow DAGs for automated model training, observing how workflows execute reliably without manual intervention.
5. Example: ML Pipeline for Spam Detection
Stepwise Implementation:
- Data Ingestion : Fetch SMS dataset from UCI repository
- Preprocessing : Clean text, tokenize, remove stopwords, apply TF-IDF
- Feature Engineering : Include n-grams and term frequency vectors
- Model Training : Train Naive Bayes classifier with cross-validation
- Evaluation : Compute F1-score and confusion matrix
- Deployment : Package model with Flask API for real-time predictions
- Monitoring : Track new message accuracy and retrain model weekly
Practical Insight :- Riya notices that automating preprocessing and retraining reduces pipeline runtime from 3 hours to 30 minutes, enabling faster iteration and production updates.
6. Best Practices for ML Pipelines
- Modularize Steps : Each pipeline stage should be independent and reusable.
- Version Control : Keep track of datasets, features, and models.
- Logging : Capture metrics, errors, and intermediate outputs.
- Monitoring : Detect model drift and data distribution changes.
- Scalability : Design pipelines to handle large datasets efficiently.
At CuriosityTech Nagpur, learners implement modular pipelines using Python classes and functions, ensuring reproducibility and scalability.
7. Advanced Workflow Automation Techniques
- Continuous Integration/Continuous Deployment (CI/CD) :- Automate training, testing, and deployment
- Hyperparameter Optimization :- Integrate tuning steps into pipelines
- A/B Testing for Models :- Deploy multiple versions and measure performance
- Automated Data Validation :- Ensure incoming data meets quality standards
Scenario Storytelling :- Arjun integrates MLflow and Airflow to track experiments and schedule retraining. When new customer data arrives, models are retrained automatically, evaluated, and deployed without manual intervention.
8. Real-World Applications
| Industry | Pipeline Use Case | Benefit |
| Finance | Fraud detection | Automate feature extraction, retrain daily |
| Healthcare | Disease prediction | Ensure pipelines comply with reproducibility standards |
| Retail | Recommendation systems | Real-time model updates for changing inventory |
| Autonomous Vehicles | Object detection models | Continuous retraining with sensor data |
| NLP | Spam detection / sentiment analysis | Automatically update models with new text |
CuriosityTech.in emphasizes end-to-end workflow automation to prepare students for enterprise ML challenges.
9. Key Takeaways
- ML pipelines streamline the model lifecycle and reduce manual errors.
- Automation ensures reproducibility, scalability, and faster iteration.
- Modular design, monitoring, and versioning are mandatory for production ML.
- Hands-on projects help bridge theory with industry practices.
Conclusion
ML pipelines and workflow automation are critical skills for ML engineers in 2025. Mastery allows engineers to:
- Build robust, reproducible workflows.
- Deploy and monitor models efficiently.
- Scale ML solutions for enterprise-level applications.
CuriosityTech.in provides guided workshops, pipeline exercises, and hands-on automation projects, ensuring learners gain practical industry-ready skills. Contact +91-9860555369 or contact@curiositytech.in to start building automated ML pipelines.

