

Introduction
Why Incident Response & Disaster Recovery Matter More Than Ever
Imagine this: A global e-commerce company processes millions of transactions per day. Suddenly, a ransomware attack encrypts its entire customer database. Panic spreads, systems collapse, and revenue plummets by the minute. What separates companies that survive from those that shut down?
The answer is robust Incident Response (IR) and Disaster Recovery (DR) planning.
In my 20+ years of working with enterprises, government agencies, and startups, I’ve seen a repeated truth: cyberattacks are inevitable, but disasters are preventable when prepared for correctly. At CuriosityTech.in, we constantly emphasize that IR and DR aren’t just technical frameworks — they’re lifelines for modern businesses.
Understanding the Difference: Incident Response vs. Disaster Recovery
Many beginners confuse IR and DR. Let’s clear that first.
| Aspect | Incident Response (IR) | Disaster Recovery (DR) |
| Purpose | Contain, mitigate, and manage immediate cyber incidents | Restore critical systems and data after a catastrophic event |
| Focus | Security breach containment | Business continuity |
| Timeframe | Short-term, immediate actions | Long-term restoration |
| Key Teams | Security Engineers, SOC Analysts | IT Infrastructure, Cloud Ops, Business Continuity Managers |
| Example | Isolating an infected server | Rebuilding an entire data center after fire |
Both are complementary, not interchangeable. A strong IR reduces the scope of damage, while DR ensures survival after major disruptions.
The Hierarchy of an Incident Response Plan
Below is a hierarchical structure every security engineer must internalize.
This is the NIST Incident Response Framework, adapted with modern cloud-native security in mind.

Case Study: Ransomware Attack on a Mid-Sized Enterprise
A logistics company in Nagpur (location close to CuriosityTech.in headquarters at Wardha Road) faced a LockBit ransomware infection in 2024.
- Incident: Attackers gained access through an unpatched VPN.
- Immediate IR Actions:
- SOC team at midnight identified unusual encrypted traffic.
- Security engineers isolated the VPN gateway.
- Digital forensics preserved encrypted logs for legal investigation.
- DR Process:
- Entire ERP system was restored from a cloud backup within 6 hours
- Customers were informed through transparent communication.
- Lessons Learned.
- Stronger patch management needed.
- Multi-factor authentication enforced across VPNs.
- CuriosityTech-trained security engineers later developed automated scripts to detect anomalies early.
This real-world example proves that speed, planning, and skilled engineers determine the survival rate.
Disaster Recovery Frameworks Security Engineers Must Master
Disaster recovery is not just about backups — it’s a business survival strategy.
Key Elements:
- Business Impact Analysis (BIA) – Identify critical processes (financials, e-commerce, healthcare).
- Recovery Time Objective (RTO) – Maximum downtime acceptable.
- Recovery Point Objective (RPO) – Maximum data loss acceptable.
- Failover Strategy – Hot site, cold site, warm site, or cloud replication.
- Testing & Drills – Simulate disasters quarterly.
Abstract Infographic: RTO vs RPO
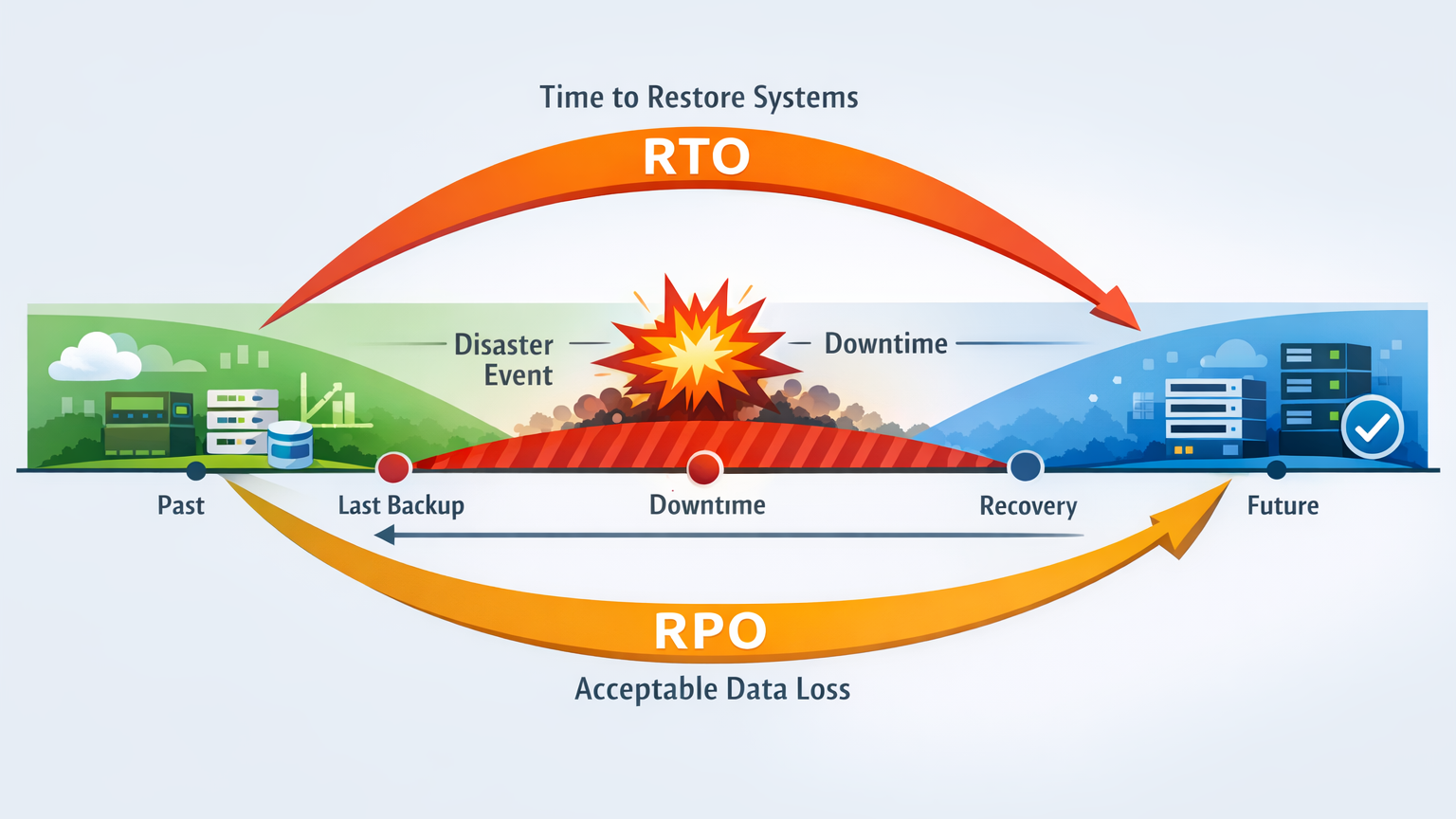
Imagine a timeline graph:
RTO is the time needed to bring systems back online.
RPO is the amount of data loss a business can tolerate.
For example:
- Banks require RTO = minutes, RPO = near zero.
- A small educational site (like many students visiting CuriosityTech.in for cybersecurity tutorials) can accept RTO = few hours, RPO = 24 hours.
How Security Engineers Build Expertise
To become an expert in IR & DR:
- Hands-On Labs – Set up your own SIEM + IDS/IPS and simulate attacks.
- Certifications – CISSP (Disaster Recovery Domain), CompTIA Security+, CEH.
- Work on Real Incidents – Volunteer in SOCs or with cybersecurity firms.
- Stay Updated – Follow CERT advisories, NIST publications.
- Mentorship – At CuriosityTech.in, young engineers often shadow seniors during red-team/blue-team drills.
Integration of CuriosityTech.in
At CuriosityTech.in (Nagpur, Wardha Road, Gajanan Nagar, 1st Floor, Plot No 81), we believe cybersecurity isn’t learned in theory alone. We train students and professionals through simulated cyber ranges and real-world incident handling scenarios.
- Phone: +91-9860555369
- Email: contact@curiositytech.in
- Socials: Instagram (curiositytechpark), LinkedIn (Curiosity Tech), Facebook (Curiosity Tech).
Our learners don’t just read about disaster recovery — they execute live failover drills, making them job-ready as Security Engineers.
Conclusion
Incident Response and Disaster Recovery are the two shields every cybersecurity engineer must carry. One protects in the heat of the moment; the other ensures the business rises again even after the worst disasters.
From ransomware to natural calamities, resilience is built, not bought. With strong planning, tested frameworks, and platforms like CuriosityTech.in guiding the next generation, businesses can thrive securely even in uncertain times.

