
Introduction
In 2025, supervised learning remains the foundation of machine learning, forming the core of tasks like sales prediction, spam detection, and medical diagnosis. At Curiosity Tech (Nagpur, Wardha Road, Gajanan Nagar), beginners often ask:
“How do regression and classification differ? Which one should I use for my ML project?”
This blog answers these questions in depth, blending conceptual clarity, real-world examples, and hands-on project storytelling. By the end, you’ll understand both regression and classification in practice, not just theory.
1. What is Supervised Learning?
Supervised learning is a type of machine learning where the model is trained on labeled data—data that contains input features and known outputs.
- Goal: Predict outputs for unseen inputs.
- Applications in 2025:
- Fraud detection in banking
- Customer churn prediction
- House price forecasting
- Disease diagnosis
At Curiosity Tech, we often tell students: “Supervised learning is like teaching a child using flashcards—show examples, let the system learn patterns, and then test it on new cases.”
2. Types of Supervised Learning
Supervised learning is primarily divided into two types:
| Type | Purpose | Output | Real-World Example |
| Regression | Predict continuous values | Numeric | Predicting house prices, temperature, or stock market value |
| Classification | Predict discrete categories | Class labels | Spam detection, loan approval, disease diagnosis |
3. Regression Explained
Definition: Regression predicts a continuous numeric output based on input features.
Common Algorithms:
- Linear Regression
- Polynomial Regression
- Support Vector Regression (SVR)
- Decision Tree Regression
Scenario Storytelling: Riya, a beginner ML student at CuriosityTech Park, wants to predict house prices in Nagpur. She collects data on:
- Area in sq. ft.
- Number of bedrooms
- Location ratings
- Age of the house
By training a Linear Regression model, she predicts house prices for new properties. The model uses the relationship between features and price to forecast accurately.
Equation (for Linear Regression):
y=β0+β1×1+β2×2+⋯+βnxny = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \dots + \beta_n x_ny=β0+β1x1+β2x2+⋯+βnxn
- yyy → Target variable (house price)
- xix_ixi → Input features (area, bedrooms, etc.)
- βi\beta_iβi → Learned coefficients
4. Classification Explained
Definition: Classification predicts discrete categories rather than continuous values.
Common Algorithms:
- Logistic Regression
- Decision Trees
- Random Forest
- K-Nearest Neighbors (KNN)
- Support Vector Machines (SVM)
Scenario Storytelling: Arjun, an ML engineer student at CuriosityTech.in, wants to build a spam detection system.
- Input: Email content
- Output: “Spam” or “Not Spam”
He trains a Logistic Regression classifier, transforming text data into features (using TF-IDF or Bag-of-Words) and labels (0 for Not Spam, 1 for Spam).
Key Concept: Classification evaluates accuracy, precision, recall, and F1-score instead of continuous error metrics.
5. Regression vs Classification Table
| Aspect | Regression | Classification |
| Output | Continuous values | Discrete classes |
| Examples | House price, stock price | Email spam, loan approval |
| Metrics | MSE, RMSE, R² | Accuracy, Precision, Recall, F1-score |
| Algorithms | Linear, Polynomial, SVR | Logistic Regression, SVM, Decision Tree |
| Real-World Application | Predicting sales, forecasting weather | Disease detection, sentiment analysis |
6. Flow Diagram (Supervised Learning Pipeline)
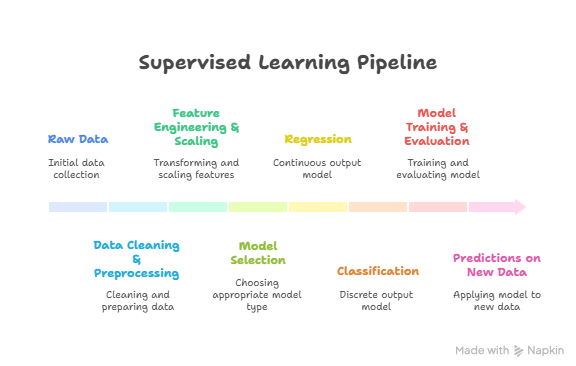
At CuriosityTech.in Nagpur, we ensure students practice this entire supervised learning pipeline with multiple datasets to understand nuances of regression and classification.
7. Mini Project Example: Customer Churn Prediction
Problem: Predict if a customer will churn (classification).
Steps at CuriosityTech Labs:
- Data Loading: CSV from telecom company
- Preprocessing: Handle missing values, scale numeric features, encode categorical variables
- Train-Test Split: 80%-20%
- Model Selection: Logistic Regression
- Evaluation: Accuracy, Confusion Matrix
Python Snippet:
from sklearn.linear_model import LogisticRegression
sklearn.model_selection import train_test_split
sklearn.metrics import accuracy_score, confusion_matrix
# X = features, y = labels
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(“Accuracy:”, accuracy_score(y_test, y_pred))
print(“Confusion Matrix:\n”, confusion_matrix(y_test, y_pred))
Observation: Students learn how preprocessing, feature selection, and algorithm choice directly affect accuracy.
8. Practical Tips from CuriosityTech Experts
- Always visualize data before choosing regression or classification.
- For regression, check correlation between features and target.
- For classification, balance the classes to avoid bias.
- Experiment with multiple algorithms; no single algorithm works best for all datasets.
- Document each step: cleaning, scaling, and encoding decisions matter for real-world pipelines.
9. Real-World Applications
| Type | Application | Industry |
| Regression | Predicting house prices | Real Estate |
| Regression | Stock market forecasting | Finance |
| Classification | Spam detection | IT & Email Services |
| Classification | Loan approval | Banking |
| Classification | Disease diagnosis | Healthcare |
At CuriosityTech.in, our learners work on all these applications with hands-on datasets, ensuring readiness for interviews and production-level deployment.
10. Key Takeaways
- Supervised learning uses labeled data to learn patterns.
- Regression predicts continuous outputs; classification predicts categories.
- Proper preprocessing, feature engineering, and evaluation are mandatory for accurate predictions.
- Hands-on projects, like spam detection or churn prediction, help transition theory into real-world ML skills.
At CuriosityTech Nagpur, mentorship and practical exercises ensure learners internalize these concepts before advancing to unsupervised learning or deep learning modules.
Conclusion
Regression and classification are core building blocks of supervised learning. By mastering them, learners gain the ability to:
- Solve real-world problems in finance, healthcare, and IT.
- Understand model performance metrics.
- Build robust ML pipelines ready for deployment.
Contact Curiosity Tech via +91-9860555369 or contact@curiositytech.in to start your practical supervised learning journey with guided mentorship and real-world dataset