

Introduction
Natural Language Processing (NLP) is the bridge between human language and machines. From chatbots to sentiment analysis, NLP powers many modern AI applications. Unlike image data, text is sequential, sparse, and complex, requiring specialized neural network architectures like RNNs, LSTMs, and Transformers.
At CuriosityTech.in in Nagpur, beginners start their NLP journey by building end-to-end pipelines—from text preprocessing to model deployment. This approach ensures students not only understand the theory but can also implement real-world NLP projects that are highly valued in the AI job market.
1. What is NLP?
Natural Language Processing is the art and science of teaching machines to understand, interpret and generate human language.
Core Challenges:
- Ambiguity in language (e.g., “bank” = river bank or financial bank?)
- Context understanding (word meaning depends on surrounding words)
- Sequential dependencies (long sentences or paragraphs)
Applications:
- Sentiment analysis (positive/negative reviews)
- Machine translation (English → Spanish)
- Chatbots and virtual assistants (Alexa, Siri)
- Text summarization and information retrieval
2. NLP Pipeline (Step-by-Step)
Workflow Diagram (Textual Representation):– Raw Text → Text Cleaning → Tokenization → Embedding → Model Training → Evaluation → Deployment
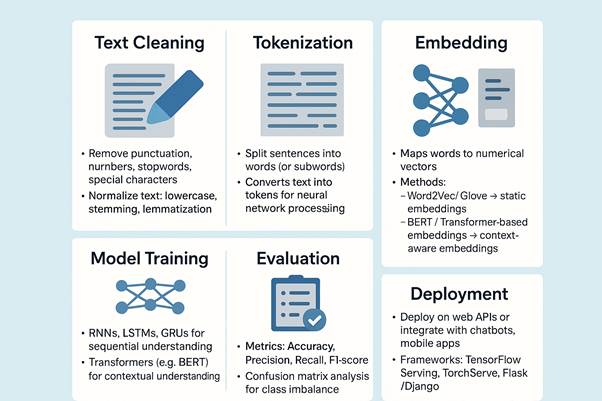
3. Practical Example: Sentiment Analysis
Objective: Classify movie reviews as positive or negative.
Python + Keras Implementation:
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
# Example data
reviews = [“I loved the movie”, “I hated the movie”]
labels = [1, 0] # 1 = positive, 0 = negative
# Tokenization
tokenizer = Tokenizer(num_words=1000)
tokenizer.fit_on_texts(reviews)
sequences = tokenizer.texts_to_sequences(reviews)
padded = pad_sequences(sequences, maxlen=5)
# Model
model = Sequential([
Embedding(input_dim=1000, output_dim=64, input_length=5),
LSTM(128),
Dense(1, activation=’sigmoid’)
])
model.compile(optimizer=’adam’, loss=’binary_crossentropy’, metrics=[‘accuracy’])
model.fit(padded, labels, epochs=10)
Observation: This small pipeline introduces beginners to tokenization, embeddings, sequential modeling, and prediction, all essential for real-world NLP tasks.
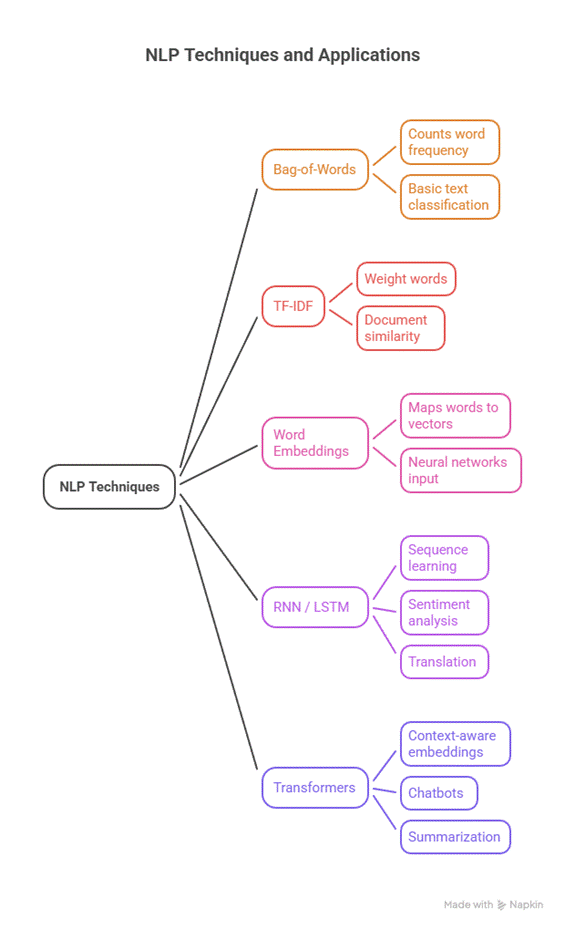
4. NLP Techniques and Methods
6. Career Perspective
- NLP Engineers are in high demand due to the explosion of textual data
- Employers expect experience in :-
- Preprocessing pipelines
RNNs/LSTMs for sequence modeling
Transformers for contextual tasks
- Deployment and API integration
- Preprocessing pipelines
Mentorship Tip: At CuriosityTech.in, learners are guided to document and deploy NLP projects, ensuring they can demonstrate real-world AI skills to recruiters.
7. Human Story
A beginner at CuriosityTech initially struggled with understanding context in text sequences. After working on LSTM-based sentiment analysis and integrating BERT embeddings, the student successfully built a chatbot that could answer multi-turn questions, highlighting the importance of hands-on experience with sequential modeling in NLP.
Conclusion
NLP with deep learning is critical for AI engineers in 2025, especially with the growing demand for chatbots, sentiment analysis, and text-based AI applications. Building practical pipelines—from text cleaning to model deployment—prepares learners to tackle real-world problems. Platforms like CuriosityTech.in provide the mentorship, projects, and tools necessary to transition from beginner to career-ready NLP expert.