

Introduction
Deploying AI models is just the beginning. To make AI systems reliable and enterprise-ready, engineers must focus on scaling and monitoring. Scaling ensures that models handle increasing loads, while monitoring maintains performance, accuracy, and compliance over time.
AtCuriosity Tech.in, learners in Nagpur gain hands-on experience in production-level AI pipelines, understanding both technical and operational aspects, which are essential for advanced AI careers in 2025.
1. Why Scaling AI Models Matters
AI models in production face challenges that differ from training:
- High request volumes requiring fast inference
- Concurrent users interacting with applications simultaneously
- Data drift affecting model performance over time
Analogy: A restaurant may prepare dishes perfectly in a small setting, but scaling to hundreds of customers requires kitchen optimization, workflow monitoring, and quality checks—similar to AI production pipelines.
CuriosityTech Insight: Learners are trained to think beyond model accuracy, focusing on infrastructure, scalability, and maintainability.
2. Scaling AI Models
Horizontal vs Vertical Scaling
| Scaling Type | Description | Use Case |
| Horizontal | Add more servers or instances | Cloud deployment handling more API requests |
| Vertical | Upgrade server resources (CPU, RAM, GPU) | High-performance inference tasks |
Batch vs Online Inference
- Batch: Process multiple inputs together for efficiency
- Online/Real-Time: Serve predictions instantly for individual requests
Load Balancing & Orchestration
- Use load balancers to distribute incoming requests
- Use Kubernetes or Docker Swarm for container orchestration
- Ensures high availability and fault tolerance
3. Monitoring AI Models in Production
Monitoring is critical to detect:
- Model Drift: Changes in input data distribution
- Prediction Errors: Increased misclassifications or anomalies
- Latency Issues: Slow responses impacting user experience
Tools & Techniques:
- Prometheus + Grafana: Real-time metrics visualization
- TensorFlow Model Analysis (TFMA): Monitor model performance by slices of data
- Custom Logging: Track inputs, outputs, and performance metrics
CuriosityTech Example: Students implement real-time dashboards to monitor accuracy, latency, and drift for deployed models.
4. Handling Model Drift
Model drift occurs when real-world data deviates from training data, causing degraded performance.
Strategies:
- Continuous Evaluation: Compare predictions against ground truth
- Retraining Pipelines: Automatically retrain models on new data
- Alert Systems: Notify engineers when performance drops
Practical Insight: CuriosityTech students set up alerts for drift detection, ensuring production AI remains reliable and accurate.
5. Enterprise Production Pipeline
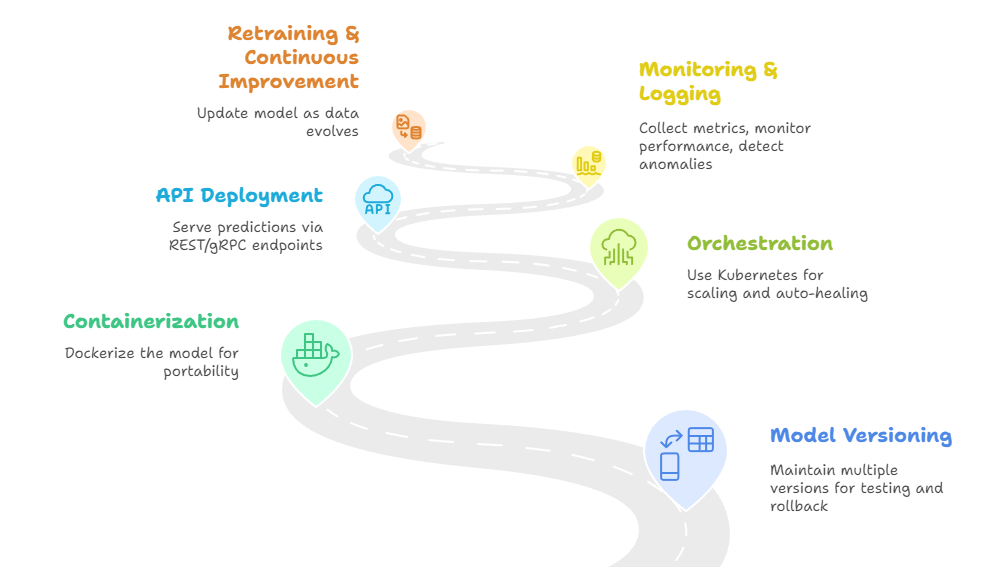
Step 1 – Model Versioning: Maintain multiple versions for testing and rollback
Step 2 – Containerization: Dockerize the model for portability
Step 3 – Orchestration: Use Kubernetes for scaling and auto-healing
Step 4 – API Deployment: Serve predictions via REST/gRPC endpoints
Step 5 – Monitoring & Logging: Collect metrics, monitor performance, detect anomalies
Step 6 – Retraining & Continuous Improvement: Update model as data evolves
Textual Diagram:
6. Human Story
A student deployed a CNN-based defect detection model for a factory. Initially, the system handled low-volume requests, but when real-time demand surged, latency increased, causing delays. By implementing horizontal scaling and load balancing, the system efficiently handled hundreds of requests per minute. This experience highlighted the importance of operational readiness in AI production.
7. Career Insights
- Knowledge of scaling and monitoring AI models distinguishes engineers in industry
- Key skills expected by employers:
- Kubernetes, Docker, and cloud deployment
API development for serving predictions
Performance monitoring and drift detection
- Retraining pipelines and CI/CD integration
- Kubernetes, Docker, and cloud deployment
Portfolio Tip: CuriosityTech students create full production pipelines for their projects, demonstrating both AI expertise and operational excellence—highly valued in interviews.
Conclusion
Scaling and monitoring AI models are critical for enterprise-grade AI applications. Through hands-on projects at CuriosityTech.in, learners gain experience in building robust pipelines, monitoring real-time performance, and maintaining model reliability, ensuring they are career-ready for advanced AI engineering roles.

