

Introduction
Reinforcement Learning (RL) is a cutting-edge branch of Machine Learning where agents learn to make decisions by interacting with an environment and receiving feedback in the form of rewards or penalties. Unlike supervised learning, RL focuses on sequential decision-making and long-term strategies, making it crucial for applications in robotics, gaming, autonomous systems, and finance.
At Curiosity Tech, Nagpur (1st Floor, Plot No 81, Wardha Rd, Gajanan Nagar), learners explore RL from fundamentals to advanced applications, gaining hands-on experience with OpenAI Gym, Python RL libraries, and real-world simulations.
This blog provides a deep conceptual understanding of RL, key components, algorithms, workflows, and practical insights, preparing learners for advanced data science projects in 2025.
Section 1 – What is Reinforcement Learning?
Definition: RL is a learning paradigm where an agent learns optimal actions to maximize cumulative rewards in an environment.
Key Features:
- Agent: The decision-maker or learner
- Environment: The world the agent interacts with
- Action: Choices the agent can take
- State: Current situation or context of the agent
- Reward: Feedback signal guiding learning
Curiosity Tech Story:
Learners trained an RL agent to play Tic-Tac-Toe, then scaled it to simulate stock trading strategies, demonstrating how RL can adapt to dynamic environments.
Section 2 – Reinforcement Learning vs Other ML Types
| Aspect | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
| Data | Labeled | Unlabeled | Feedback via rewards |
| Goal | Predict output | Discover structure | Maximize cumulative reward |
| Interaction | None | None | Continuous interaction with environment |
| Example | House price prediction | Customer segmentation | Game AI, robot navigation |
Insight: RL is ideal for dynamic, sequential decision-making tasks, where consequences of actions are delayed.
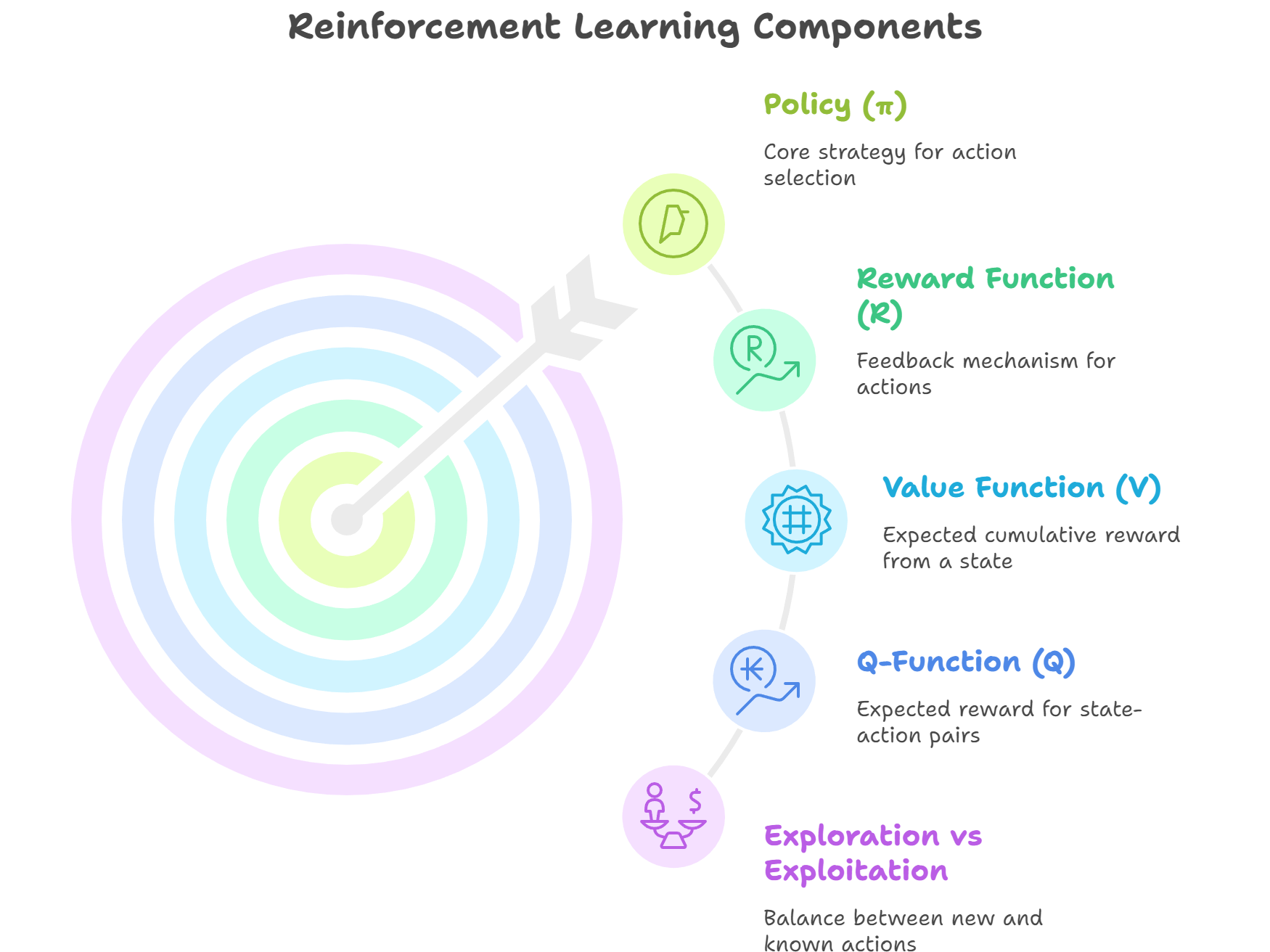
Section 3 – Core Concepts
- Policy (π): Strategy mapping states to actions
- Reward Function (R): Provides feedback for each action
- Value Function (V): Expected cumulative reward from a state
- Q-Function (Q): Expected reward for a state-action pair
- Exploration vs Exploitation: Trade-off between trying new actions and using known strategies
Diagram Description:
Section 4 – Popular RL Algorithms
| Algorithm | Type | Use Case |
| Q-Learning | Model-Free, Value-Based | Simple discrete environments like Tic-Tac-Toe |
| Deep Q-Networks (DQN) | Deep RL, Value-Based | High-dimensional environments, games |
| Policy Gradient Methods | Policy-Based | Continuous action spaces, robotics |
| Actor-Critic | Hybrid (Value+Policy) | Real-time control, complex environments |
| Proximal Policy Optimization (PPO) | Advanced Policy-Based | Industry-standard in robotics & gaming |
Curiosity Tech Insight: Learners implement Q-Learning on grid-world environments to understand value iteration and reward shaping before moving to deep RL.
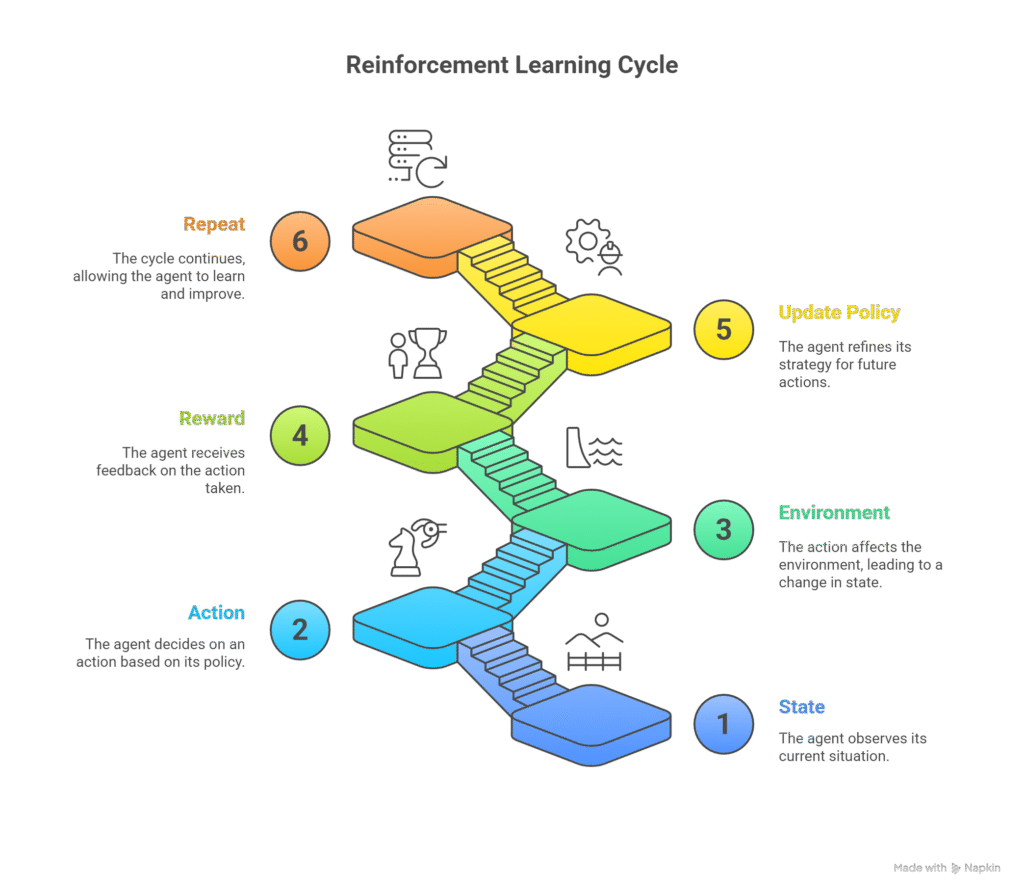
Section 5 – Reinforcement Learning Workflow
1 – Define Environment:
- Use OpenAI Gym or custom environments
- Define state space, action space, and rewards
2 – Choose Algorithm:
- Discrete environments → Q-Learning
- Complex or continuous → PPO, DDPG, Actor-Critic
3 – Train Agent:
- Initialize Q-table or neural network
- Agent interacts with environment, updating policy via reward signals
4 – Evaluate Performance:
- Plot cumulative rewards over episodes
- Adjust hyperparameters for convergence and stability
5 – Deploy and Monitor:
- Integrate RL agent in real-world simulations or games
- Continuously monitor performance and environment changes
Section 6 – Practical Example: Q-Learning in Python
import numpy as np
import gym
env = gym.make(“FrozenLake-v1”, is_slippery=False)
q_table = np.zeros((env.observation_space.n, env.action_space.n))
alpha = 0.1
gamma = 0.99
epsilon = 0.1
episodes = 1000
for _ in range(episodes):
state = env.reset()[0]
done = False
while not done:
if np.random.uniform(0,1) < epsilon:
action = env.action_space.sample() # Explore
else:
action = np.argmax(q_table[state]) # Exploit
next_state, reward, done, _, _ = env.step(action)
q_table[state, action] = q_table[state, action] + alpha * (reward + gamma * np.max(q_table[next_state]) – q_table[state, action])
state = next_state
Outcome: Learners observe how agents improve performance over episodes, reinforcing RL concepts practically.
Section 7 – Tips for Mastering RL
- Understand reward shaping and exploration strategies
- Start with simple discrete environments (e.g., grid-world)
- Gradually move to high-dimensional or continuous tasks
- Experiment with different algorithms and hyperparameters
- Document learning experiments for portfolio and research projects
Curiosity Tech Story:
Learners trained RL agents for autonomous warehouse robots, optimizing task completion time while avoiding collisions, demonstrating practical deployment of RL in industry.
Conclusion
Reinforcement Learning is a powerful tool for sequential decision-making and adaptive problem solving. Mastery of RL requires understanding core concepts, algorithms, workflows, and iterative experimentation.
At Curiosity Tech Nagpur, learners practice RL hands-on, implement Q-Learning, DQN, and PPO, and apply it to gaming, robotics, and simulation projects, preparing them for advanced data science careers in 2025. Contact +91-9860555369, contact@curiositytech.in, and follow Instagram: CuriosityTech Park or LinkedIn: Curiosity Tech for guidance.

