

Introduction
Reinforcement Learning (RL) is one of the most exciting areas of Machine Learning in 2025, powering applications from autonomous vehicles to game AI and robotics. Unlike supervised learning, RL focuses on learning by interaction—an agent learns what actions to take to maximize cumulative rewards in an environment.
AtCuriosity Tech (Nagpur, Wardha Road, Gajanan Nagar), learners get hands-on exposure to RL fundamentals and practical examples to understand the entire loop of agent-environment interaction.
1. What is Reinforcement Learning?
Definition: RL is a type of machine learning where an agent learns optimal behavior by interacting with an environment to maximize cumulative rewards over time.
Key Elements:
| Element | Description | Example |
| Agent | Learner or decision maker | Robot, AI player |
| Environment | Where the agent operates | Game board, simulation, real-world |
| State (s) | Representation of environment | Position on a chessboard |
| Action (a) | Choices agent can make | Move left, move right |
| Reward (r) | Feedback from environment | +1 for goal, -1 for obstacle |
| Policy (π) | Strategy mapping states to actions | π(s) = best action |
| Value Function (V) | Expected cumulative reward from state | Helps evaluate states |
Curiosity Tech Insight: Students learn that RL is different from supervised learning because there is no explicit label, only feedback (reward) guiding learning.
2. Types of Reinforcement Learning
- Model-Free RL: Learns directly from experience without modeling the environment
- Q-Learning: Value-based, learns action-value function Q(s,a)
- SARSA: State-Action-Reward-State-Action, similar to Q-learning but on-policy
- Q-Learning: Value-based, learns action-value function Q(s,a)
- Model-Based RL: Builds a model of the environment and uses it to plan actions
- Policy Gradient Methods: Learn a policy directly without value function
- Reinforce Algorithm
- Actor-Critic methods
- Reinforce Algorithm
Scenario Storytelling:
Arjun at Curiosity Tech implements a Q-Learning agent for a grid-world game, learning to reach a goal while avoiding obstacles.
3. RL Workflow Diagram
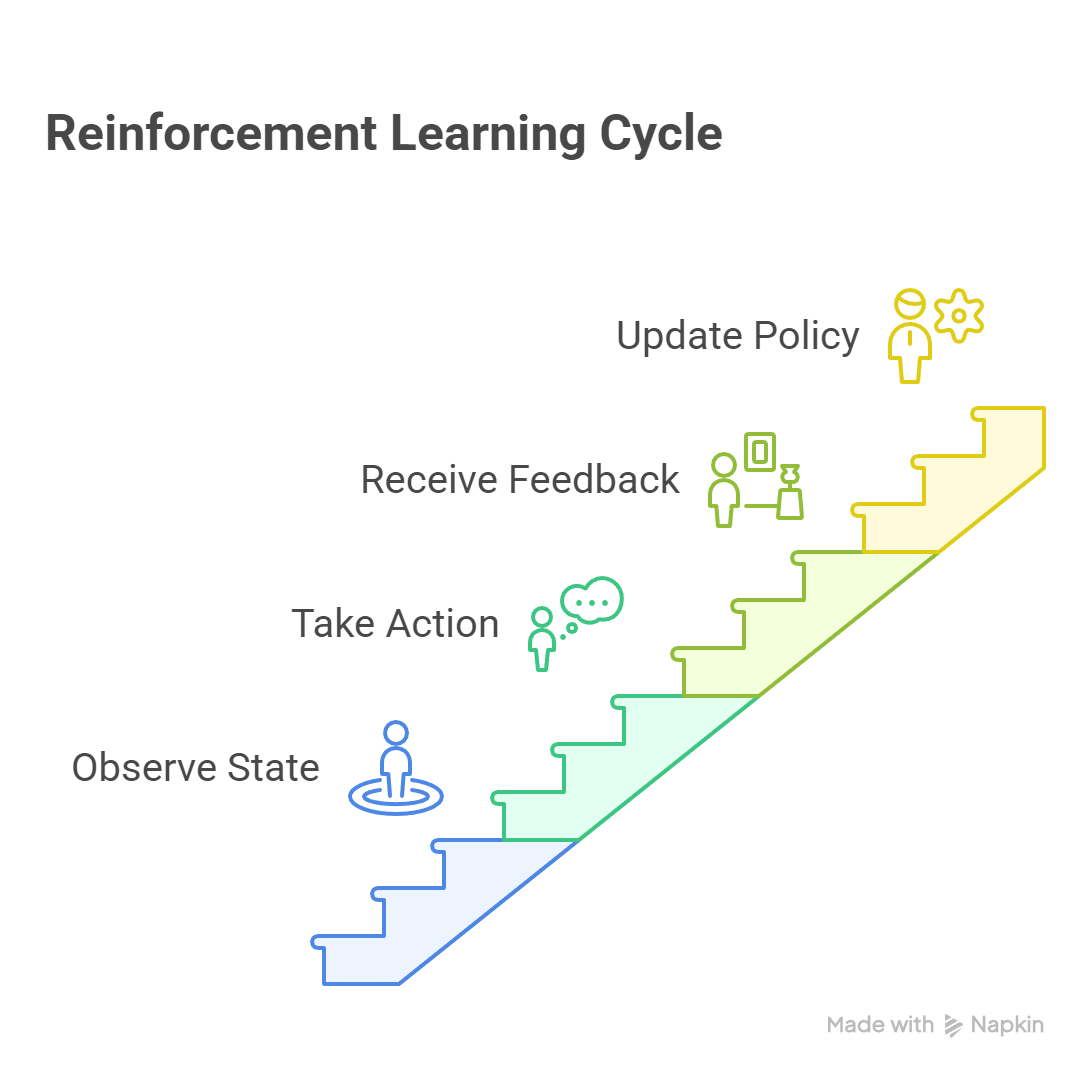
Explanation:
- Agent observes state from the environment
- Takes action based on policy
- Environment returns next state and reward
- Agent updates policy based on experience
4. Key Algorithms
| Algorithm | Type | Description | Use Case |
| Q-Learning | Value-based | Learn optimal Q(s,a) | Grid-world, simple games |
| SARSA | Value-based | On-policy learning | Games with stochastic rewards |
| DQN (Deep Q-Network) | Deep RL | Q-Learning with neural networks | Atari games, robotics |
| REINFORCE | Policy Gradient | Directly optimize policy | Simple control tasks |
| Actor-Critic | Hybrid | Combines policy & value function | Complex control tasks |
Curiosity Tech Insight: Learners start with tabular Q-Learning before moving to deep RL, ensuring strong conceptual foundations.
5. Practical Example: Q-Learning for Grid World
Stepwise Implementation:
- Define the environment (grid, start, goal, obstacles)
- Initialize Q-table (state-action values)
- Set learning parameters: α (learning rate), γ (discount factor), ε (exploration)
- Iteratively update Q-values based on rewards
- Evaluate policy after training
Python Snippet:
import numpy as np
# Environment settings
n_states = 6
actions = [0,1] # left, right
Q = np.zeros((n_states, len(actions)))
alpha = 0.1
gamma = 0.9
epsilon = 0.2
n_episodes = 1000
# Reward for each state
rewards = np.array([0,0,0,0,0,1])
for episode in range(n_episodes):
state = 0
done = False
while not done:
# Epsilon-greedy
if np.random.rand() < epsilon:
action = np.random.choice(actions)
else:
action = np.argmax(Q[state])
next_state = state + 1 if action == 1 else max(0, state-1)
reward = rewards[next_state]
Q[state, action] += alpha * (reward + gamma * np.max(Q[next_state]) – Q[state, action])
state = next_state
if state == n_states – 1:
done = True
print(“Trained Q-Table:\n”, Q)
Practical Insight: Riya at Curiosity Tech Park observes the Q-table converging, enabling the agent to consistently reach the goal efficiently.
6. Challenges in Reinforcement Learning
- Exploration vs Exploitation: Balancing trying new actions vs. using known rewards
- Sparse Rewards: Delayed rewards make learning difficult
- High-Dimensional State Space: Requires function approximation (deep RL)
- Sample Efficiency: RL often needs a large number of interactions
- Stability and Convergence: Complex environments may lead to unstable policies
7. Real-World Applications
| Domain | Application |
| Gaming | AlphaGo, Chess, Atari games |
| Robotics | Path planning, manipulation tasks |
| Autonomous Vehicles | Self-driving car decision-making |
| Finance | Portfolio optimization, trading strategies |
| Healthcare | Treatment planning, resource allocation |
Curiosity Tech trains learners to implement RL in simulated environments, gradually progressing to real-world applications like robotics and autonomous systems.
8. Best Practices for Beginners
- Start with simple environments (grid-world, FrozenLake)
- Use tabular RL before deep RL
- Visualize rewards and policy evolution
- Tune hyperparameters (learning rate, discount factor, epsilon) carefully
- Track exploration-exploitation balance
9. Key Takeaways
- RL focuses on learning optimal actions via rewards
- Core components: agent, environment, state, action, reward, policy, value function
- Beginners should start with tabular Q-Learning before moving to deep RL
- RL has real-world applications in gaming, robotics, finance, healthcare
- Hands-on practice is crucial to understand environment dynamics and policy learning
Conclusion
Reinforcement Learning is a powerful paradigm in machine learning, enabling systems to learn from interaction. Mastery involves understanding concepts, algorithms, and practical implementation.
At Curiosity Tech, learners receive hands-on training with RL environments, Python implementations, and real-world scenario applications. Contact +91-9860555369 or contact@curiositytech.in to explore Reinforcement Learning projects and training in 2025.

