

Introduction
In 2025, advanced machine learning techniques are essential for building high-performance models. Among these, ensemble methods and boosting algorithms stand out because they combine multiple models to improve accuracy, reduce bias, and enhance robustness.
At curiositytech.in Nagpur (1st Floor, Plot No 81, Wardha Rd, Gajanan Nagar), learners master ensemble learning strategies, from simple bagging to complex boosting methods like XGBoost, LightGBM, and CatBoost, applying them to real-world datasets for predictive modeling.
This blog provides a deep exploration of ensembles, boosting techniques, practical workflows, visualizations, and implementation tips.
Section 1 – What is Ensemble Learning?
Definition: Ensemble learning combines multiple individual models (weak learners) to create a stronger, more accurate predictive model.
Why Ensemble Learning Works:
- Reduces variance (bagging)
- Reduces bias (boosting)
- Improves generalization on unseen data
CuriosityTech Story: Learners combined decision trees to predict customer churn, achieving a 5–10% higher accuracy than a single model, demonstrating the power of ensembles in practical scenarios.
Section 2 – Types of Ensemble Methods
| Method | Description | Common Algorithms |
| Bagging | Train multiple models independently and average predictions | Random Forest, Bagged Trees |
| Boosting | Train models sequentially; each corrects errors of previous | AdaBoost, XGBoost, LightGBM, CatBoost |
| Stacking | Combine predictions of multiple models using a meta-model | Stacked Regressor/Classifer |
| Voting | Combine predictions by majority vote or averaging | Hard/Soft Voting Classifiers |
Insight: Bagging improves stability, boosting improves accuracy, and stacking leverages heterogeneous models.
Section 3 – Bagging: Random Forest
Workflow:
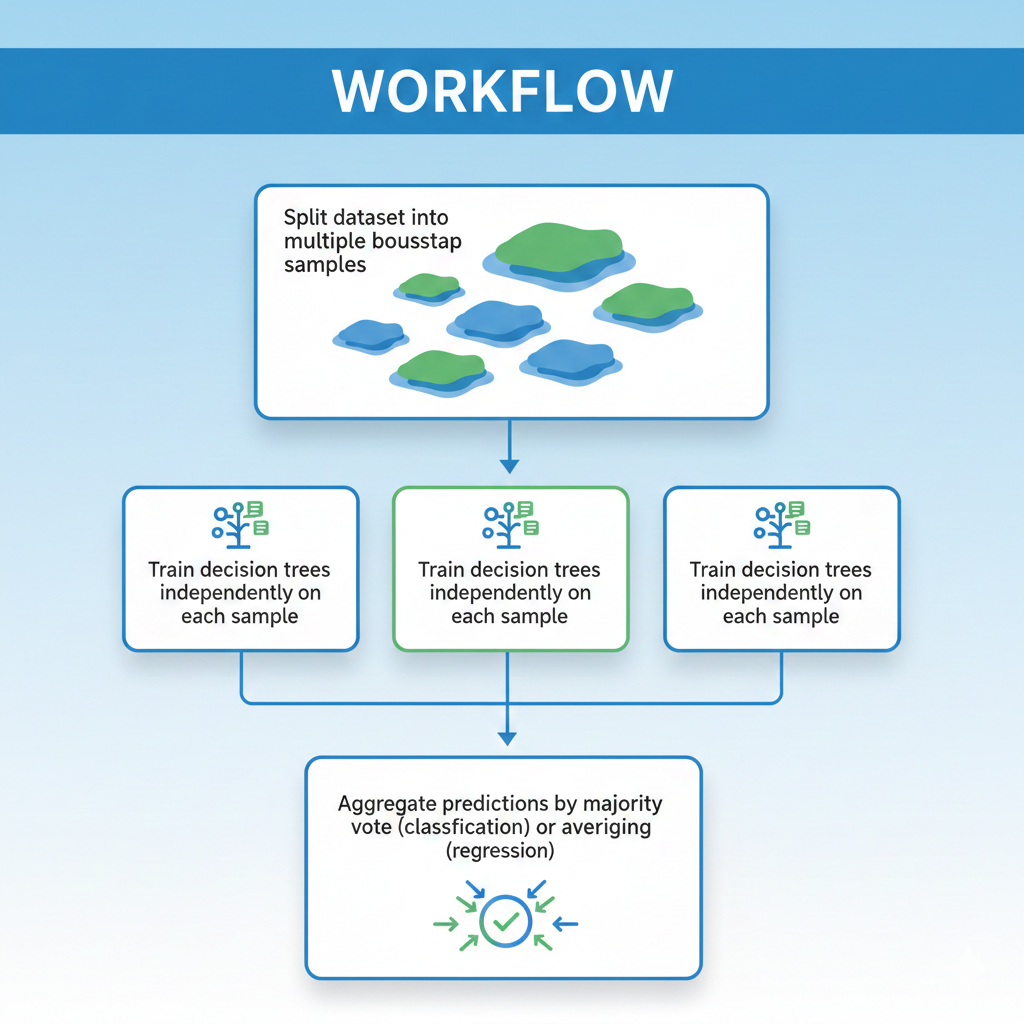
Python Example:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Random Forest model
rf = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
print(“Accuracy:”, accuracy_score(y_test, y_pred))
Visualization:
- Feature importance can be plotted to understand key predictive variables.
- Bagging reduces overfitting compared to single decision trees.
Section 4 – Boosting: Sequential Model Improvement
Definition: Boosting trains models sequentially, with each new model focusing on errors made by previous models.
Popular Boosting Algorithms:
- AdaBoost: Adjusts weights for misclassified instances
- Gradient Boosting: Optimizes residual errors using gradient descent
- XGBoost: Faster, regularized gradient boosting
- LightGBM: Efficient, handles large datasets with leaf-wise growth
- CatBoost: Handles categorical features natively
Python Example – XGBoost:
import xgboost as xgb
from sklearn.metrics import roc_auc_score
xgb_model = xgb.XGBClassifier(n_estimators=200, learning_rate=0.05, max_depth=4)
xgb_model.fit(X_train, y_train)
y_pred = xgb_model.predict(X_test)
print(“ROC-AUC:”, roc_auc_score(y_test, y_pred))
Visualization:
- Use XGBoost feature importance plots
- Plot training and validation error over boosting rounds to monitor performance
Section 5 – Comparison: Bagging vs Boosting
| Aspect | Bagging | Boosting |
| Approach | Parallel training | Sequential training |
| Goal | Reduce variance | Reduce bias and variance |
| Overfitting | Less prone | Can overfit if not regularized |
| Speed | Faster (parallel) | Slower (sequential) |
| Example | Random Forest | AdaBoost, XGBoost |
Insight: Bagging is ideal for unstable models, while boosting is best for highly accurate predictive tasks.
Section 6 – Stacking and Voting
Stacking Workflow:
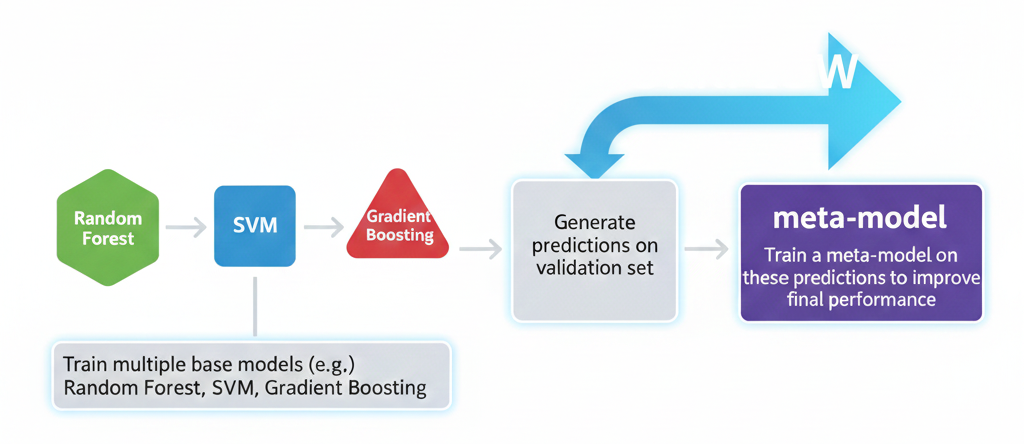
- Train multiple base models (e.g., Random Forest, SVM, Gradient Boosting)
- Generate predictions on validation set
- Train a meta-model on these predictions to improve final performance
Voting:
- Combine predictions from multiple models
- Hard Voting: Majority vote for classification
- Soft Voting: Average predicted probabilities
CuriosityTech Story:- Learners implemented stacked ensemble for sales prediction, outperforming single models and boosting methods alone, showcasing real-world application of advanced ensemble techniques.
Section 7 – Tips for Mastering Ensembles & Boosting
- Start with Random Forest for understanding bagging
- Explore XGBoost and LightGBM for high-accuracy predictions
- Experiment with hyperparameters like learning rate, tree depth, and number of estimators
- Use cross-validation to prevent overfitting
- Visualize feature importance and learning curves
- Build portfolio projects combining bagging, boosting, and stacking
CuriosityTech Insight:- Learners use ensemble techniques in finance, e-commerce, and healthcare datasets, building robust predictive models for real-world scenarios.
Section 8 – Real-World Applications
- Finance: Credit scoring and fraud detection
- Healthcare: Disease prediction and risk scoring
- E-commerce: Customer churn prediction
- Marketing: Campaign effectiveness modeling
Visualization Example:
- Plot ROC curves for multiple models on the same graph to compare ensemble performance
- Feature importance bar charts highlight most influential predictor
Conclusion
Advanced ML techniques like ensembles and boosting allow data scientists to build highly accurate, stable, and interpretable models. Mastery of these methods is essential for competitive 2025 data science careers.
At curiositytech.in Nagpur, learners implement bagging, boosting, and stacking techniques on real-world datasets, gaining hands-on experience, visualization skills, and portfolio-ready projects. Contact +91-9860555369, contact@curiositytech.in and follow Instagram: CuriosityTech Park or LinkedIn: Curiosity Tech for further guidance.