

Introduction
Machine Learning in 2025 is not just about algorithms; it’s about choosing the right approach for the right problem. Two fundamental paradigms dominate: Supervised Learning and Unsupervised Learning.
At Curiosity Tech, Nagpur (1st Floor, Plot No 81, Wardha Rd, Gajanan Nagar), we help learners understand the differences deeply, so they can select appropriate models and workflows in real-world projects.
This blog explains the differences, applications, workflows, and analogies, giving a clear understanding for beginners and intermediate learners.
Section 1 – What is Supervised Learning?
Definition: Supervised Learning is a machine learning paradigm where the algorithm is trained on labeled data, meaning each input has a corresponding output.
Analogy: Think of a student learning with a teacher. The teacher shows the student questions (inputs) and correct answers (outputs). The student learns to predict the answer for new questions.
Characteristics:
- Requires labeled datasets
- Predicts outputs for new inputs
- Includes regression and classification tasks
Example:- Predicting house prices based on features like size, location, and number of bedrooms.
Section 2 – What is Unsupervised Learning?
Definition: Unsupervised Learning is a paradigm where the algorithm learns patterns in unlabeled data, without explicit output.
Analogy: A student explores a library and groups books by similarities without prior guidance on genres.
Characteristics:
- No labels needed
- Focuses on finding hidden structures
- Includes clustering and dimensionality reduction
Example: Segmenting customers into groups for targeted marketing without knowing labels like “high-value” or “low-value” in advance.
Section 3 – Key Differences Between Supervised and Unsupervised Learning
| Features | Supervised Learning | Unsupervised Learning |
| Data Requirements | Labeled | Unlabeled |
| Goals | Predict or classify outcomes | Discover hidden patterns |
| Output | Specific target variable | Structure, clusters, associations |
| Algorithms | Linear Regression, Logistic Regression, Decision Trees, Random Forest | K-Means, Hierarchical Clustering, PCA |
| Evaluation | Accuracy, RMSE, F1 Score | Silhouette Score, Explained Variance |
| Complexity | Can be simpler with labeled data | Often requires domain knowledge to interpret |
| Use Case Example | Loan approval, sales prediction | Customer segmentation, anomaly detection |
Visual Analogy Description:
- Imagine two playgrounds:
- Supervised: Teacher stands beside students and corrects mistakes.
- Unsupervised: Students explore and self-organize into groups based on similarities.
- Supervised: Teacher stands beside students and corrects mistakes.
Section 4 – Applications and Real-World Examples
Supervised Learning:
- Finance: Predicting credit risk (approve/decline loans)
- Healthcare: Predict patient readmission or disease diagnosis
- Retail: Predict customer purchase likelihood
Story Example: At Curiosity Tech, a learner worked on predicting loan defaults. Using a labeled dataset of past applicants, the model predicted high-risk applicants, reducing bank losses by 12%.
Unsupervised Learning:
- Marketing: Segment customers into meaningful groups for personalized campaigns
- Cybersecurity: Detect anomalous behavior for fraud detection
- Bioinformatics: Identify patterns in gene expression data
Story Example: Curiosity Tech learners applied K-Means clustering on e-commerce customer data. The model discovered three distinct groups of customers: bargain hunters, loyal buyers, and high-value frequent shoppers. Marketing strategies were then tailored for each group, increasing engagement by 20%.
Section 5 – Workflow Differences
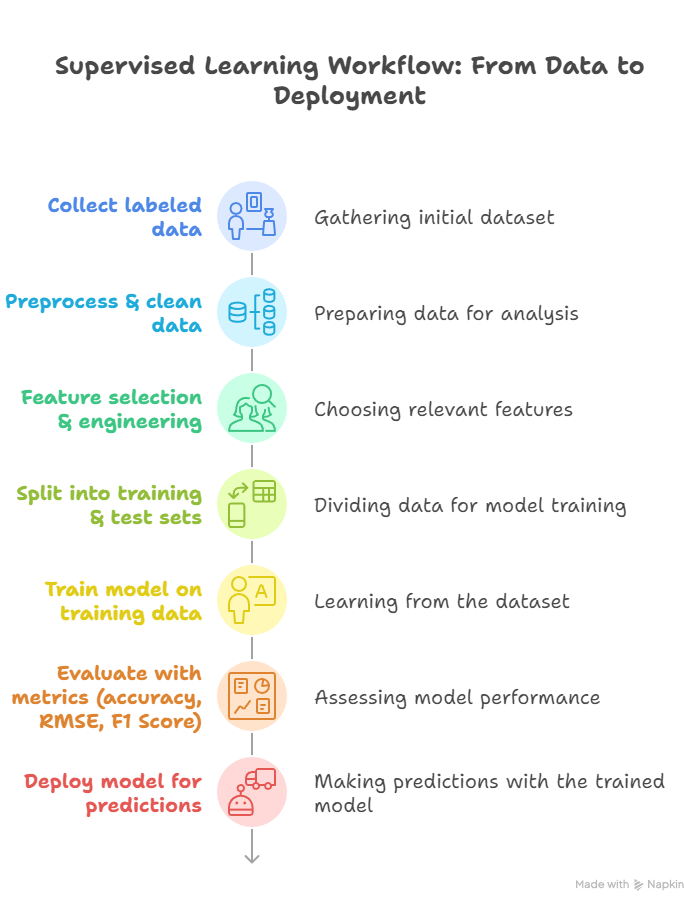
Supervised Learning Workflow:
- Collect labeled data
- Preprocess & clean data
- Feature selection & engineering
- Split into training & test sets
- Train model on training data
- Evaluate with metrics (accuracy, RMSE, F1 Score)
- Deploy model for predictions
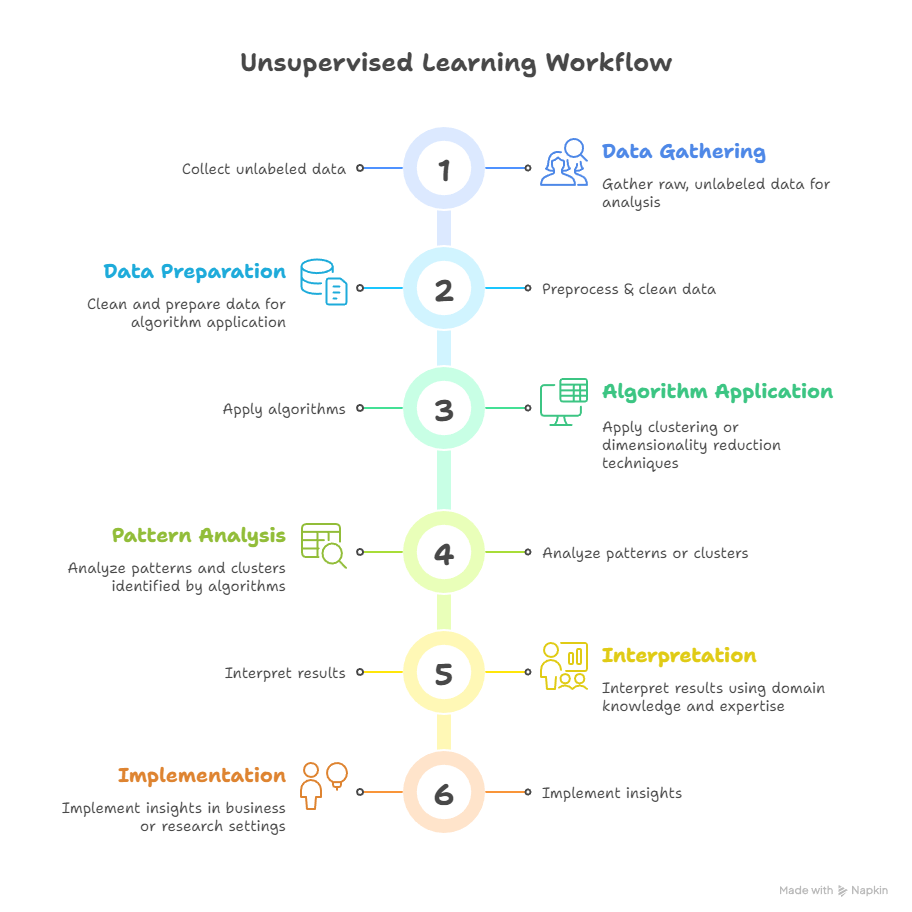
Unsupervised Learning Workflow:
- Collect unlabeled data
- Preprocess & clean data
- Apply clustering or dimensionality reduction algorithms
- Analyze patterns or clusters
- Interpret results using domain knowledge
- Implement insights in business or research
Section 6 – Choosing the Right Approach
Tips from CuriosityTech Mentors:
- If you have historical labeled data and a prediction goal, use Supervised Learning.
- If you want to discover patterns in unknown data, use Unsupervised Learning.
- Often, hybrid approaches can be used: for example, clustering followed by classification.
- Always visualize your data first—EDA is crucial to understand the structure.
Section 7 – Hands-On Mini Example
Supervised Learning (Python Example): Predicting House Prices
from sklearn.linear_model import LinearRegression
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
Unsupervised Learning (Python Example): Customer Segmentation
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
clusters = kmeans.fit_predict(customer_data)
customer_data[‘Segment’] = clusters
Outcome:
- Supervised: Model predicts precise outcomes
- Unsupervised: Model reveals hidden structure
Section 8 – Tips to Master Both
- Learn common supervised algorithms: Linear Regression, Logistic Regression, Random Forest
- Practice clustering and PCA for unsupervised learning
- Combine Python, Pandas, Scikit-Learn, Seaborn for EDA + ML
- Work on real datasets from Kaggle, UCI, or company projects
- Document insights, especially for unsupervised learning where interpretation is key
- At CuriosityTech.in Nagpur, learners apply both paradigms in live projects, building strong portfolios for 2025 careers
Conclusion
Understanding Supervised vs Unsupervised Learning is essential for any data scientist. Each paradigm serves different goals: prediction vs pattern discovery. Mastering both equips you to solve a wide variety of business and research problems.
At Curiosity Tech, we provide mentored, project-based learning that ensures students practically understand and apply both paradigms, preparing them for real-world challenges and careers in data science. Contact us at +91-9860555369, contact@curiositytech.in, and follow Instagram: CuriosityTechPark or LinkedIn: Curiosity Tech for updates.

