

Introduction
High Availability (HA) and failover strategies are critical for building resilient cloud applications. Google Cloud Platform (GCP) provides a suite of services and configurations to ensure minimal downtime, data integrity, and uninterrupted user experience even during failures. At Curiosity Tech engineers are trained to design and implement HA architectures that combine redundancy, load balancing, automated failover, and multi-region deployment, preparing applications for enterprise-scale workloads.
What is High Availability (HA)?
High Availability refers to a system’s ability to remain operational and accessible for a high percentage of time. In cloud environments, this typically involves:
- Redundancy: Duplicate critical components
- Fault Tolerance: Continue operation despite failures
- Scalability: Handle sudden traffic spikes
- Disaster Recovery: Maintain continuity during outages
Key Metrics:
- Uptime Percentage: e.g., 99.95% (corresponds to ~22 minutes downtime/year)
- Recovery Time Objective (RTO): Maximum acceptable downtime
- Recovery Point Objective (RPO): Maximum acceptable data loss
Core Strategies for HA in GCP
| Strategy | Explanation |
| Load Balancing | Distribute traffic across multiple instances or regions using Cloud Load Balancer. |
| Auto-Scaling | Automatically scale compute resources based on demand using GKE, Compute Engine, or Cloud Run. |
| Multi-Zone Deployments | Deploy resources across multiple zones within a region for redundancy. |
| Multi-Region Deployments | Deploy across regions for disaster recovery and low-latency access. |
| Managed Services | Use Cloud SQL, Firestore, BigQuery, which provide built-in HA. |
| Monitoring & Alerts | Detect failures quickly using Cloud Monitoring & Logging. |
High Availability Services in GCP
| Service | HA Feature |
| Cloud Load Balancing | Distributes traffic globally or regionally, supports automatic failover. |
| GKE Clusters | Node auto-repair, multi-zone clusters for fault tolerance. |
| Cloud SQL | High-availability configuration with primary/replica nodes. |
| Cloud Storage | Multi-region replication and object versioning. |
| Cloud Spanner | Globally-distributed database with synchronous replication. |
| Cloud Pub/Sub | Event-driven, resilient message delivery. |
Diagram Concept: High Availability Architecture
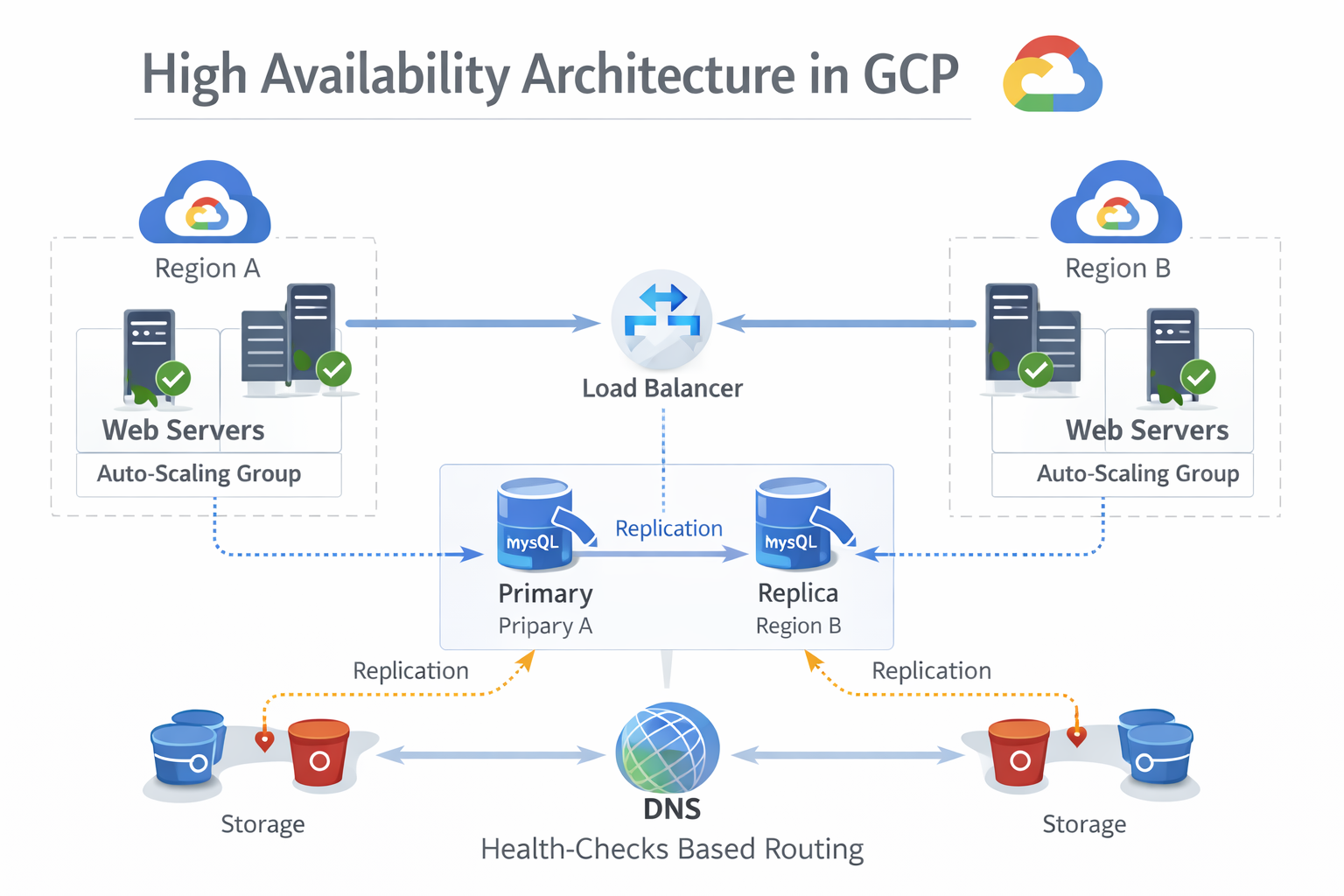
Failover Mechanisms in GCP
Failover ensures that when a component or service fails, traffic or workload is automatically redirected to a healthy resource.
- Compute Failover:
- Use Managed Instance Groups (MIGs) with auto-healing.
- Instances in multiple zones ensure availability if one zone fails.
- Database Failover:
- Cloud SQL HA: Primary instance in one zone, standby in another. Automatic failover if primary fails.
- Cloud Spanner: Synchronous replication across multiple regions for zero downtime.
- Application Failover:
- Multi-region deployment using Cloud Load Balancing.
- Use health checks to detect unhealthy instances and route traffic away.
- DNS Failover:
- Use Cloud DNS with health checks to reroute users to backup regions during regional outages.
Practical Example: E-Commerce Application HA Setup
Scenario: An e-commerce platform with web servers, APIs, and databases.
- Web Servers (Cloud Run / GKE):
- Multi-zone deployment, autoscaling enabled.
- Global HTTP(S) Load Balancer for user requests.
- Database (Cloud SQL):
- HA configuration with failover replica in a separate zone.
- Daily backups and automated failover testing.
- Storage (Cloud Storage):
- Multi-region bucket for images, static assets, and backups.
- Object versioning enabled to prevent data loss.
- Monitoring & Alerts:
- Cloud Monitoring for uptime, latency, and error rates.
- Notifications via Pub/Sub or email for immediate incident response.
Table: Key HA & Failover Components
| Component | HA Strategy | Failover Mechanism |
| Web Servers | Multi-zone, auto-scaling | Load balancer detects unhealthy instances |
| Database | Primary/replica, backups | Automatic failover to standby instance |
| Storage | Multi-region replication | Object versioning & lifecycle policies |
| DNS | Health-check based routing | Redirect traffic to healthy regions |
Best Practices for HA & Failover
- Use Managed Services Whenever Possible: Reduces operational complexity and improves reliability.
- Distribute Workloads Across Zones and Regions: Prevent single points of failure.
- Implement Health Checks & Monitoring: Detect issues proactively.
- Automate Failover Testing: Simulate outages regularly to validate recovery procedures.
- Plan for Disaster Recovery: Define RTO, RPO, and backup strategies.
- Leverage Multi-Region Load Balancers: Ensure global users experience minimal latency.
- Optimize Costs While Ensuring Availability: Avoid over-provisioning resources unnecessarily.
Advanced Strategies
- Blue-Green & Canary Deployments: Deploy new versions in parallel to existing versions, then switch traffic gradually.
- Cross-Region Replication for Databases: Spanner or Firestore multi-region replication ensures zero downtime during region failures.
- Serverless HA Architectures: Use Cloud Run with multi-region deployments and Cloud Functions for event-driven workloads.
- Auto-Scaling & Auto-Healing Policies: Automatically replace failed nodes and scale resources to meet demand.
Conclusion
High Availability and failover strategies in GCP are essential for resilient, production-grade applications. By combining multi-zone and multi-region deployments, managed services, load balancing, and automated monitoring, engineers can ensure continuous service availability, minimal downtime, and business continuity. At Curiosity Tech , engineers practice designing end-to-end HA architectures with hands-on labs, learning to handle failures gracefully, implement redundancy, and optimize for cost and performance, making them well-prepared for enterprise cloud environments

